MySQL
一. 数据库基本概率(理论)
1. 概念
1.1 数据Date
描述事物的符号记录 -- 数字,字符文本,图像,音频,视频类等 [二进制格式数据]
1.2 数据库DataBase – 简称DB
保存数据的“仓库” [大量数据集中存储]
两大特性: "集成性" 和"共享性"
集成性 -- 数据与数据的联系一起保存
共享性 -- 在网络应用中共享数据,[为了不同的应用需求,使用不同的开发语言,在同一个时间访问同一个数据]
1.3 数据库管理系统DMBS
英语全名 - [DataBase Management System]
主流的DBMS软件:
[方言] MySql,Oracle,MS SqlServer [2000,20xxx],Sybase,informix,DB2...
主要功能:
(1)数据库的建立和维护功能
(2)数据定义功能
(3)数据操纵功能 - SQL语言 [数据查询统计和数据更新两个方面]
(4)数据库的运行管理功能
(5)通信功能
1.4 数据库用户User
数据库管理 - DBA
应用程序员 - Programmer开发人员
终端用户 - User
1.5 数据库系统DBS
DBS英文全文 - [DataBase System]
数据库系统(DatabaseSystem,DBS)是一个人机系统,一般由硬件、操作系统、数据库、DBMS、应用软件和数据库用户(包括数据库管理员)组成
2. 数据库发展史
发展的三个阶段:
(1) 层次型和网状型 -- 代表产品是1969年IBM公司研制的层次模型数据库管理系统IMS
(2) 关系型数据型库 -- 使用二维表格的形式来存放数据 【主流】
(3) 关系 + 对象型 -- [必须支持面向对象,具有开放性,能够在多个平台上使用]
管理技术的3个阶段
(1) 人工管理
(2) 文件管理
(3) 数据库系统
3. 数据库分类
3.1 关系型数据库
"关系型数据库"
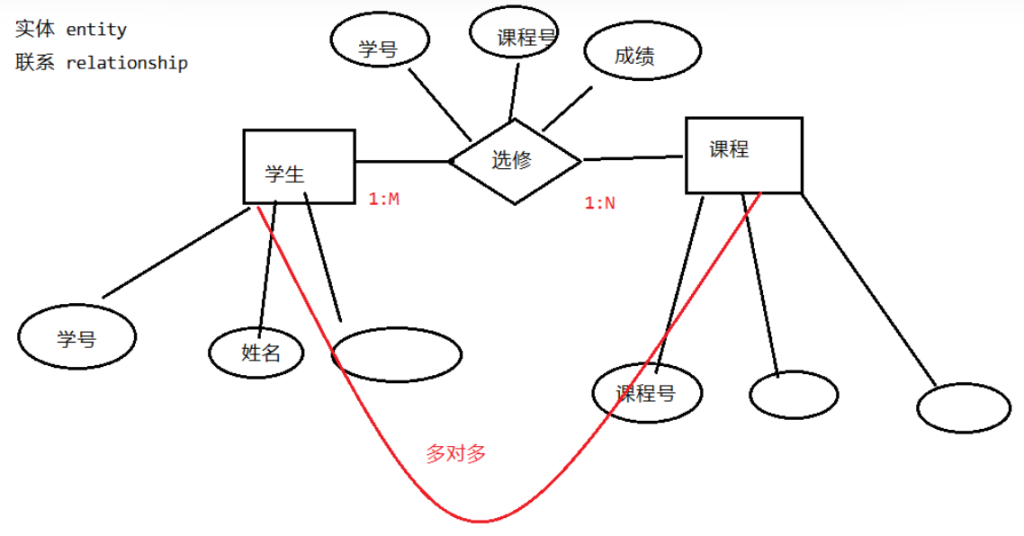
实体 : 记录(行) 表示了一个实体(的属性)
而E-R图:实体与实体之间的联系(关系)
即 表与表的关系
3.2 非关系型数据库
非关系型数据库'NoSQL' [Not Only SQL 不仅仅是SQL] -高并发场景
不使用表来保存数据,使用key-value [键值对数据库]
"sid":1
"sname":"张三"
"stu01" - {"1":1,"sname":"张三","ssex":"男"}
NoSQL的代表产品:
(1)Redis
|-1.几乎覆盖了Memcached的绝大部分功能
2.数据都在内存中,支持持久化,主要用做备份恢复
3.除了支持简单的key-value模式,还支持多种数据结构的存储,比如:list,set,hash,zset等.
4.一般是作为缓存数据库辅助持久化的数据库
(2)MongoDB
|-1.高性能,开源,模式自由的开发型数据库
2.数据都在内存中,如果内存不足,把不常用的数据保存到硬盘
3.虽然是key-value模式,但是对value(尤其是json)提供了丰富的查询功能
4.支持二进制数据及大型对象
5.可以根据数据的特点替代RDBMS,成为独立的数据库.或者配合RDBMS,存储特定的数据
二. 数据库的一些简单操作
1. 登录mysql数据库
# mysql -uroot -p
2. 查看数据库列表信息show
show databases;
3. 创建数据库create
create database 数据库名字 default character set utf8;
4. 查看正在使用的数据库select
select database();
5. 使用或者切换数据库use
use 数据库名字;
6. 查看当前数据库中的表信息show
show tables;
-- 结果 Empty set (0.00 sec)
--空集合,表示当前数据库中没有表
7. 创建表create
create table student -- 表名
(
sid int,
sname char(10), -- char类型如果不指定长度,只默认为char(1)
sage int -- 最后一列,不加‘,’
)default charset=utf8;
8. 查看表的结构desc
语法: desc 表名
-- 示例: desc student
9. 查看表中的所有行和列select
语法: select * from 表名
-- select * from student
10. 向表中添加数据 insert [列与值要数目和类型做匹配一致]
insert into 表名(列1,列2,列3....) values(值1,值2,值3....)
-- insert into student(sid,sname,sage) values(1,'张三',20);
三.Navicat可视化工具的使用
1. Navicat简介
Navicat是一套可创建多个连接的数据库管理工具,可以方便地管理MySQL、Oracle、PostgreSQL、SQLite、SQL Server、MariaDB和 MongoDB等不同类型的数据库
Navicat不是由MySQL官方提供的,是由'第三方软件公司'发布
基于MySQL的 GUI(图形用户界面)管理工具,不只是Navicat一种,还有很多种: Sqlyog,DataGrip...
2. Navicat实操
2.1 Navicat建立连接
(1)填写"连接名" 不能与已有连接名冲突
(2)主机IP,如果是localhost,则表示连接本地主机 --"127.0.0.1代表本机"
(3)用户名,密码,端口号
(4)测试连接
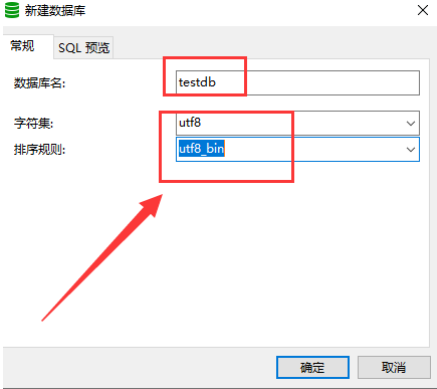
2.2 创建数据库
在"连接名"上右键-->"新建数据库"-->填写数据库名-->选字符集,确定完成
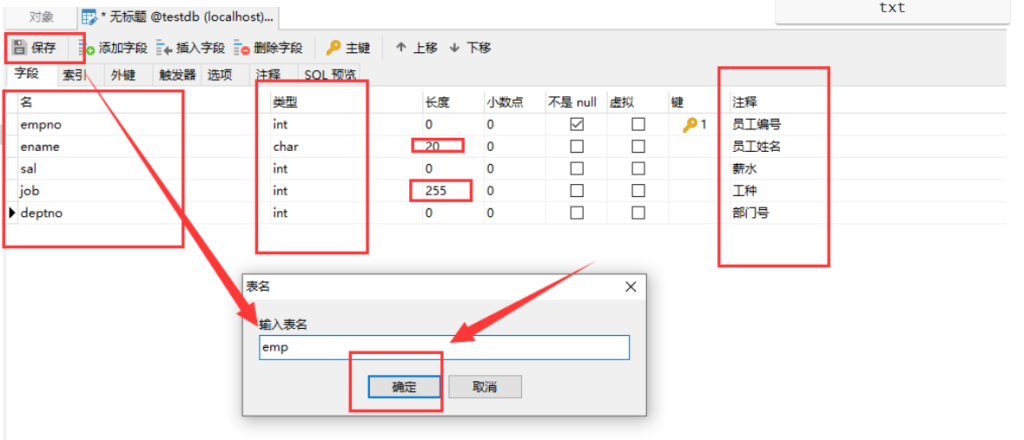
2.3 创建表
在打开的数据库目录中,选中"表"右键-->"新建表"
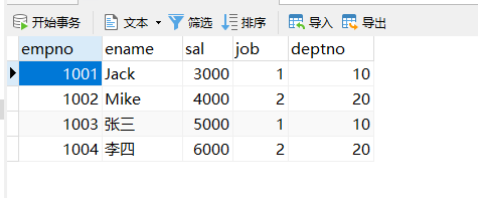
2.4 打开表–输入数据 [insert操作]
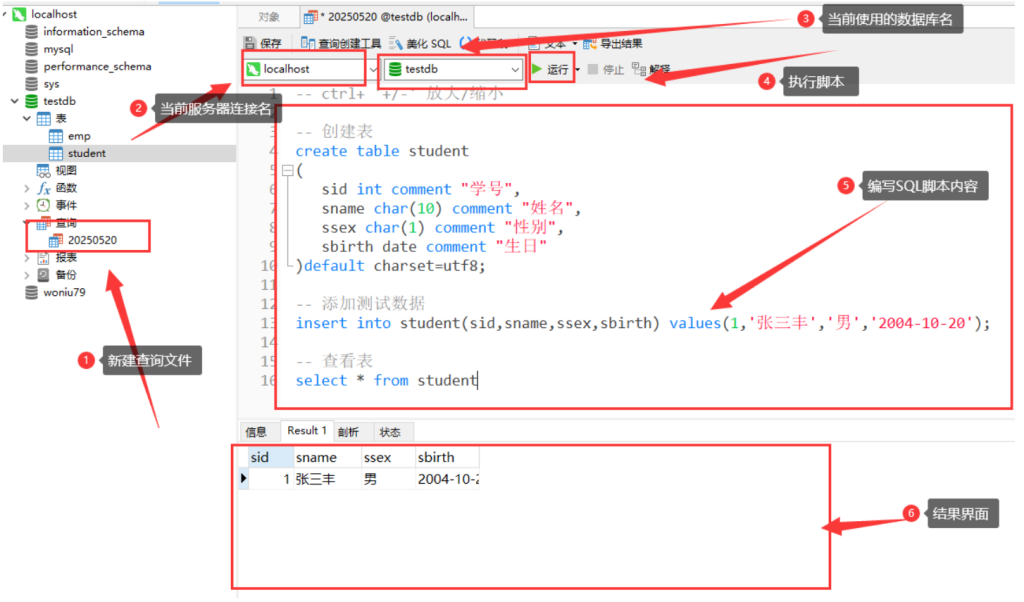
2.5 查询编辑器
当前打开的数据库目录中找到"查询" -->右键"新建查询" -->保存命名当前查询的脚本文件名
四.SQL分类
4.1 SQL定义
结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
-- 与关系模型数据库交互的语言
SQL从功能上可以分为3部分:'数据定义'、'数据操纵'和'数据控制'。
4.2 可分为六大类(*DDL,*DML,*DQL,*DCL,TCL,CCL)
*(1)DDL -- 英文全名(Data Definition Language) -- '数据定义语言'
"Create 创建,Drop 删除,Alter 修改,Truncate 截断"
*(2)DML -- 英文全名(Data Manipulation Language) -- '数据操作语言'
"Insert 插入,Delete 删除,Update 修改"
*(3)DQL -- 英文全名(Data Query Language) -- '数据查询语言'
"select [选择]"
*(4)DCL -- 英文全名(Data Control Language) -- '数据控制语言'
"grant [授权],revoke [撤销]"
--------------------------------------------------------------------------
(5)TCL -- 英文全名(Transaction Control Language) -- '事务控制语言'
"commit 提交,rollback 回滚(回退)"
(6)CCL -- 英文全名(Cursor Control Language) -- '游标(指针)控制语言'
"declare ,open ,fetch ,close"
五.MySQL数据类型(字符,整数,浮点数,二进制数据)
数据类型“字符串”,”整数”,”浮点数”,”二进制数据”
5.1 整数型
1)整数型:
tinyint 微小整数数 - 1字节 - 8位二进制 -128~127
smallint 小整数 - 2字节
mediumint 整数 - 3字节
int - 整数型 - 4字节 [Byte 8个二进制数位bit = 1字节Byte]
1024B = 1KB (千)
1024KB = 1MB (兆)
1024MB = 1GB (吉)
1024GB = 1TB
1024TB = 1PB
1024PB = 1EB
bigint 大整型 8字节
5.2 小数型
(2)小数型:
float 单精度浮点数 4字节 [近似值表示法,小数位不固定]
double 双精度浮点数 8字节
decimal(10,2)
-- 示例 12345678.99 [10表示总位数为10位,其中2位小数]
-- 对于小数点后面精度值要求高数值,比如金额,推荐使用decimal
5.3 日期型
(3)日期型:
date - '年-月-日' '2025-5-12'
time - '时:分:秒' '13:55:20'
datetime -日期时间类型 例: '2025-05-20 14:30:20'
补充: 系统函数now()/sysdate() --当前系统的日期与时间值
timestamp -- 时间戳类型
5.4 字符(串)型
(4)字符(串)型:
'xxxx'或"xxxx"
char(10) -- 固定长度的字符串型 'abc ' -最大255个字符
-- 存储效率高,以空间换效率,比如生身份证
varchar(10) -- 可变长度的字符串型 'abc' 最大65536个字符
-- 存储效率低, 以效率换空间,比如家庭住址,email
longtext 长文本类型 -- 最大4GB字符数
六.DDL详解
DDL数据定义语言:create 建表,alter 修改表,drop 删除表,truncate 截断表
6.1DDL建库建表(create)
(1)-- 创建数据库
语法:
create database 数据库名称 default character set utf8;
-- 创建库示例
create database woniu79 default character set utf8;
(2)-- 创建表
语法:
create table 表名(列名 数据类型 [,列名 类型, ...])default charset=utf8;
-- 创建表示例
create table student
(
sid int comment "学号",
sname char(10) comment "姓名",
ssex char(1) comment "性别",
sbirth date comment "生日"
)default charset=utf8;
comment 注释 注:加了comment就要在后面写注释
6.2 DDL修改表结构alter
(1)向表中添加新的字段
语法:
alter table 表名 add 新的字段名 数据类型;
-- 示例
alter table user_info add birth date;
(2)修改表中列名
语法
alter table 表名 change 旧列名 新列名 数据类型;
-- 示例
alter table user_info change birth birthday date;
(3)删除表中的列
语法
alter table 表名 drop 列名;
-- 示例
alter table user_info drop birthday;
拓展
(1)修改表中列类型方法1 change
alter table user_info change realname realname varchar(20);
(2)修改表中列类型方法2 modify
alter table user_info modify realname varchar(50)
(3)修改表名 rename
alter table user_info2 rename to userinfo
6.3 DDL删除表drop
语法
drop table [if exisits] 表名;
-- 如果删除表时,带上if exists判断,则表示如果存在才会执行删除表
-- 示例
drop table user_inifo;
drop table fi exists user_inifo; -- 先判断是否存在,存在则删除,然后再进行创建
create table user_info
(
...
)
6.4 DDL中的trunate
- 语法
truncate table 表名
-- 删除表中所有的数据
7.DML详解
DML数据操纵语言 :Insert 新增 ,Update 更新 ,Delete 删除
7.1 新增数据insert
- 语法
分为两种insert操作:
(1)-- 新增单行数据
语法:
insert into 表名(列名1,列名2,列名3....) values(值1,值2,值3);
-- 必须满足要求
a.列与值数目要匹配
b.列与值的类型要兼容
c.不能违反表中列相关的约束(限制)
(2)-- 新增多行数据
语法:
insert into 表名(列名1,列名2,列名3,.....)
values(值1,值2,值3,....),
(值1,值2,值3,....),
(值1,值2,值3,....),....;
- 示例
-- 插入单行数据
insert into user_info(id,username,realname,sex,height,balance,regtime)
values(1,'admin','张三','男',178.88,2000.99,'2025-04-30 12:33:30');
-- 插入多行数据
insert into user_info(id,username,realname,sex,height,balance,regtime)
values(2,'jenny','李四','女',168.88,3000.99,now()),
(3,'Jack','王五','男',172.88,2000.99,'2024-12-30'), (5,222,'小明','男',172.88,2000.99,'2024-12-30');
7.2 更新数据update
- 语法
update 表名 set 列名=新值 [,列=新值 ...] [where 条件]
- 示例
-- 更新所有的数据,年龄全部统一为20
update user_info set age=20
-- 更新id为1的用户年龄为22
update user_info set age=22 where id=1
-- 所有男生的年龄提高2岁
update user_info set age=age+2 where sex='男'
-- 修改更新表中的多个列
update user_info set realname='张小红',sex='女',height=165.44,balance=balance+1000
where id=4
注:where 不添加,意味着修改全部
7.3 删除数据delete
- 语法
delete from 表名 [where 条件]
注:where 不添加,将会把整个表中数据删除
- 示例
-- 删除年龄为22的用户信息
delete from user_info where age=22;
-- 删除表中所有的数据
delete from user_info;
7.4 DML中delete 与 DDL中truncate 区别
- 共同点:都可以将表中的所有数据删除
- 不同点
- delete属于DML ,Truncate 属于DDL
- delete可以带where子句,只删除部行分数据 truncate只能无条件的清空整张表数据
- delete执行效率要低于truncate语句
- delete删除数据后,再插入数据自增会继续增长 truncate表删除数据后,自增列复位(重新开始) [初始化表,截断表]
打比方说明,delete类似卸载,truncate类似恢复出产设置
8.MySQL中七大约束
8.1 自增列 auto_increment
在mysql数据库中有一种特殊的列约束,自增列
特点:
1. 自增列只能是整数型
2. 列的值由mysql服务器在插入数据时自动生成,不需要提供
3. 自增列必须是主键
-- 示例
create table user_info
(
id int primary key auto_increment, -- id 用户编号,主键[列的值不能重复,不能为空],自增
...
)
补充:
当插入数据时,第一个与第二个增长为1和2,但是当第三个数据你不自增然后自己添加编号时,比如说5,那么当插入第四个数据时你自增长的编号是6
8.2 主键 primary key
特点:
(1) 非空
(2) 值唯一 [不能重复]
(3) 一张表只能设置1个主键, 允许多个列一起作主键
(4) 通常创建的每张表都会设置主键
(5) 主键的选择--最小性(数值列),最少更改的列
-- 示例
create table user_info
(
id 类型 primary key
)
8.3 唯一值 unique
特点:
(1) 允许一个空
(2) 值唯一
(3) 一张表可以设置多个唯一键
-- 示例
create table user_info
(
id int primary key auto_increment,
username char(20) not null unique --唯一
)
8.4 非空 not null
特点:
(1) 值不能为空
(2) 可以设置多个列为非空
(3) mysql创建表时不加not null默认允许为空值
-- 示例
create table user_info
(
id int primary key auto_increment,
ssex char(1) not null -- 非空
)
8.5 默认值 default
特点:
(1) 插入数据时,不提供值便采默认值,提供值则不使用默认值
-- 示例
create table user_info
(
id int primary key auto_increment,
address varchar(50) default '湖北武汉' -- 添加默认地址为湖北武汉
)
8.6 检查约束 check新 enum老
特点:
(1) 检查 插入的数据是否符合检查约束条件(表达式)
create table user_info
(
id int primary key auto_increment,
ssex char(1) not null check(ssex='男' or ssex='女'), -- 非空,检查 新版
ssex enum('男','女') -- 检查 老版
)
注:check约束 -MySQL5.7直接不支持 CHECK 约束 老版MySQL使用enum
8.7 外键约束 foreign key
- 特点
特点:
(1) 用于建立表与表之间的关联关系
(2) 外键列不能出现引用的主键列中不存在的值
- 语法
-- alter table 添加外键
alter table 子表 add constraint fk_子表名_主表名
foregin key(外键列名) references 主表名(主键列名);
- 示例
alter table orders add constraint fk_orders_users
foregin key(user_id) references user_info(id);
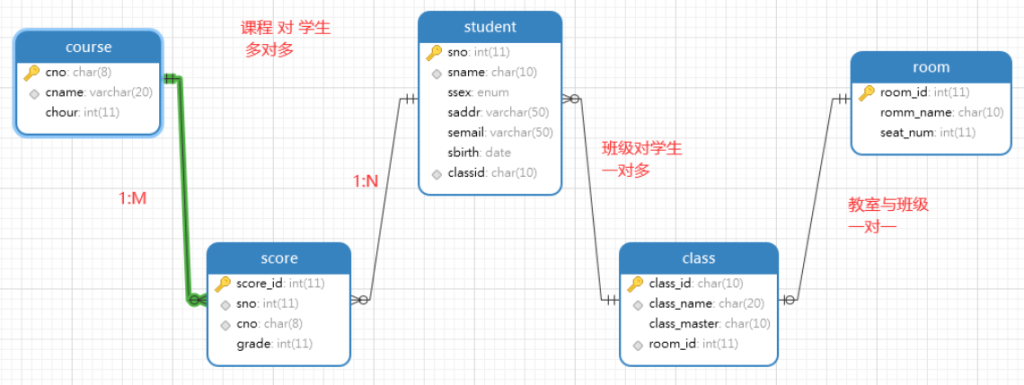
8.8 *表关系
*表关系分为三种
- 一对一
- 1:1 一边表中的一行数据与另一边表只有一行数据对应
- 另一边表中的一行数据与这边的表的数据也只有一行对应
- 举例:学生表(身份证ID-唯一) – (身份证ID-PK)身份证表
- 举例:班级表(class) – 教室表(room)
- 一对多
- 1:M 一边表中的一行数据与另一边表中的多行数据对应
- 另一边表中的一行数据与这边的表的数据也只有一行对应
- 举例:班级表 — 学生表
- 多对多
- M:N 一边表中的一行数据与另一边表中的多行数据对应
- 另一边表中的一行数据与这边的表的数据有多行对应
- 注意:多对多两张表没有直接联系,而是通过中间表进行关联
- 举例:读者 – 借阅- 图书
- 举例:学生表 -选修关系表 – 课程
9.DQL基础查询
9.1 运算符查询(算数、关系、逻辑)
- 算术运算符
算术运算符 +,-,*,/,%
- 关系运算符
6种: > , >= , <, <= , =, '<> [不等于]'
- 逻辑运算符
-- 作用: 用于连接多个条件,组合为复合条件
3种: '与and','或 or','非 not'
# 条件1 and 条件2 都为真,结果才为真
# 条件1 or 条件2 只需要1个条件为真,结果就为真
# 结果:真(1) 假(0)
9.2 查询行和列
- 查询所有行和列的数据
-- 示例
select * from student;
- 查询部份列
-- 示例
select sno,sname from student -- 查询学号和姓名两个列
- 查询的列名命名别名
select sno as '学 号',sname '姓+名',sage 年龄 -- 查询的列名命名别名
from student
9.3条件查询
- 语法
select 字段列表
from 表名
[where 条件]
-- 关系运算符(>,>=,<,<=,=,<>)和逻辑运算符(and,or,not)
1、= 等于
2、!= 不等于
3、>= 大于或等于
4、> 大于
5、< 小于
6、<= 小于或等于
7、<> 不等于
8 类似: age >= 18 and age <= 60
9、and 拼接多个条件,多个条件要同时成立
10、or 拼接多个条件,多个条件任意满足一个就可以
- 示例
-- 查询学生表中年龄在23岁以上的学生的学号,姓名,年龄和性别
select sno 学号,sname 姓名,sage,ssex 性别
from student
where sage>=23
-- 查询学生表中年龄在23岁以上的女生信息
select sno 学号,sname 姓名,sage,ssex 性别
from student
-- where not (sage>=23 and ssex='女')
-- 等价于
where sage<23 or ssex<>'女'
-- 查询学生表中年龄在23岁以上或性别是女生
select sno 学号,sname 姓名,sage,ssex 性别
from student
where sage>=23 or ssex='女'
9.4 模糊查询
(1)like与not like
— 通配符 % 用于匹配任意长度的任意字符 _ 用于匹配1个长度的任意字符
like 作为模糊查询的运算符,用于条件匹配批量的数据值
-- like 模糊匹配 not
-- 通配符
-- % 用于匹配任意长度的任意字符
-- _ 用于匹配1个长度的任意字符
-- 查询姓名中含有'小'字的学生记录
select * from student where sname like '%小%'
-- 查询姓名中不含有'小'字的学生记录
select * from student where sname not like '%小%'
-- 查询姓名中是以'小'字开头的学生记录
select * from student where sname like '小%'
select * from student where sname like '小' -- 等价于 sname='小'
-- 查询姓名中姓王,且2个字的学生信息
select * from student where sname like '王_'
-- 3字人名
select * from student where sname like '王__'
(2)between…and 与 not between… and
-- 判断某列的值是否处于某个区间范围 [数值型和日期型列]
-- 查询学生表中年龄在21~24之间学生
select * from student where sage between 21 and 24
-- 等价写法
select * from student where sage >= 21 and sage<=24
-- not between... and
select * from student where sage not between 21 and 24
-- 查询日期范围
select * from student where sbirth between '2001-1-1' and '2002-7-31'
(3)in谓词 与 not in
- 语法
语法: where 列 in (值1,值2,....)
- 示例
-- 查询classid班级号为J001,Y001,Y002任意的学生
select * from student where classid='J001' or classid='Y002' or classid='Y001'
-- 等价写法
select * from student where classid in ('J001','Y002','Y001')
select * from student where classid not in ('J001','Y002','Y001')
9.5 排序查询
- 语法
select 字段列表
from 表名
[where 条件]
[order by 要排序的列1,列2 asc|desc]
asc – 表示升序,可省略,默认为升序 desc – 表示降序,不可省略
- 示例
select * from student
order by sage asc -- asc省略时,也是升序
select * from student
order by sage desc
select * from student
order by sbirth+
-- 按中文汉字拼音顺序排序 [了解]
select * from student
order by convert(sname using GBK)
--------------------- 多列排序 [也称为分组排序]
select * from student
order by classid,sage desc -- 先按班级号升序,再到每个班中内部按年龄降序
select * from score
order by grade desc
select * from score
order by sno,grade desc -- 先按学号升序,每个学号所选修课程记录的内部按成绩降序
select * from score
order by cno,grade desc
9.6 空值查询
#空值查询 is null,is not null 仅限于 where子句
- 示例
-- 查询email为空的学生
select * from student
where semail is null
-- 查询email不为空的学生
select * from student
where semail is not null
-- 但是,如果是update的set子句,则使用=设置为空值
update student set semail=null where sno=7
9.7 去重查询distinct
#关键字: distinct
-- distinct 关键字用于查询时,屏蔽重复的数据行
select distinct sno from score
select distinct ssex from student
注:
(1)不要针对具有id的数据进行去重,没有意义
(2)distinct 并不会删除重复数据
10.DQL进阶查询
10.1系统查询
(1)字符串函数
a.concat(s1,s2)进行字符串拼接
-- CONCAT(s1,s2) 进行字符串拼接
-- 字符串拼接
select concat ('hello','world'); -- 示例
select concat(sno,'-',sname) as 学号及姓名,ssex ,sage -- 示例
from student
b.lower 将字符串所有字符变为小写
select lower('HELLO') -- 示例
c.upper 将字符串所有字符变为大写
select upper('hEllo') -- 示例
d.left 将主字符串从左边提取指定位数的子字符串
select left('abcdefg',3) -- 示例
e.right 将主字符串从右边提取指定位数的子字符串
select right('abcdefg',3) -- 示例
f.trim 去掉字符串行尾和行头的空格
select trim(' abcdefg ')
补充:
trim+right 嵌套使用 select right(trim(‘ abcdefg ‘),3)
g.字符串替换 replace(‘源字符串’,’查找子串’,’替换的字符串’)
-- 字符串替换 replace('源字符串','查找子串','替换的字符串')
select replace('abcabcabc','bc','BC')
-- 从源串中删除指定子串
select replace('abcabcabc','bc','')
h.substring/substr 返回指定的字符串
- 从源字符串的起始位置开始截取指定长度的子字符串
- substring(‘源字符串’,起始位置,截取的长度)
select substring('abcdefg',3,2) -- 起始位置从c开始
select substr('abcdefg',3,2) -- 起始位置从c开始
-- substring()如果只写起始位置,不写长度,则表示到该字符串结束
select substring(sname,2) as 名字 from student
(2)数学函数
a. abs() 返回绝对值
select abs(-3) -- 3
b. ceil()返回不小于某个值的最小整数值 【向上取整】
select ceil(3.000000001) -- 4
c. floor()返回不大于某个值的最大整数值 【向下取整]
select floor(-3.9999999) -- 结果为: -4
d. round()四舍五入取整
-- 四舍五入取整
select round(3.4)
-- 四舍五入保留小数位
select round(3.567,2)
e.MOD() 返回模,余数
select 10%3
select mod(10,3)
f. truncate() 返回数字截断小数的结果 [截位取整]
- truncate(x,y): 返回数字 x 截断y 位小数的结果, TRUNCATE 知识截断,并不是四舍五入。
select truncate(3.1291231231,0) -- 结果为3;
g. rand()随机小数
-- 生成0~1 随机小数 伪随机数 当前系统时间毫秒值 作为种子值 代入公式计算所得
select rand()
-- 0~9随机整数 [乘以10,向下取整]
select floor(rand()*10)
-- 10~20 之间随机整数
select 10+floor(rand()*11)
(3) 日期时间函数
a.week()返回给定的日期是一年中的第几周
select week(now())
b.year()返回给定日期的年份
select year(now())
c.month()返回给定日期的月份
select month(now())
d.curdate() 返回当前日期
select curdate()
e.curtime() 返回当前时间
select curtime()
f.data_add() 返回日期时间加上一个时间间隔
语法:
date_add(date,interval expr unit)
-- date: 要操作的日期或日期时间表达式。
-- INTERVAL: 关键字,表示接下来是一个时间间隔。
-- expr: 表示时间间隔的数量,可以是整数或小数。
-- unit: 时间间隔的单位,如 SECOND, MINUTE, HOUR, DAY, WEEK, MONTH,QUARTER, YEAR 等。
示例:
-- 7天之后的日期
select date_add(now(),interval 7 day)
-- 7天之前的日期
select date_add(now(),interval -7 month)
g.datediff() 返回起始时间和结束时间之间的天数
select datediff(now(),'2025-5-10')
h.last_day(date) 返回日期所在的最后一天
select last_day(now())
与date_add()联合使用示例
-- 上个月的最后一天
select last_day(now())
i.datofyear() 返回的是一年中的第几天
select dayofyear(now())
j.查询学生表中今天生日的学生信息
-- 查询学生表中今天生日的学生信息
select * from student
where month(sbirth)=month(now()) and day(sbirth)=day(now())
(4)其他函数
a.if(value,t,f)
如果 value 是真,返回 t;否则返回 f
select if(3>5,'真','假')
b.ifnull(value1,value2)
如果 value1 不为 NULL,返回 value1,否则返回 value2。
select ifnull('xxx','aaa') -- 参数1,参数2
c.version()返回当前数据库的版本
select version();
d.database()返回当前数据库名
select database();
e.user() 当前的用户名
select user()
f.password()
select password('123')
10.2 聚合函数 sum-avg-max-min-count
- 函数的种类
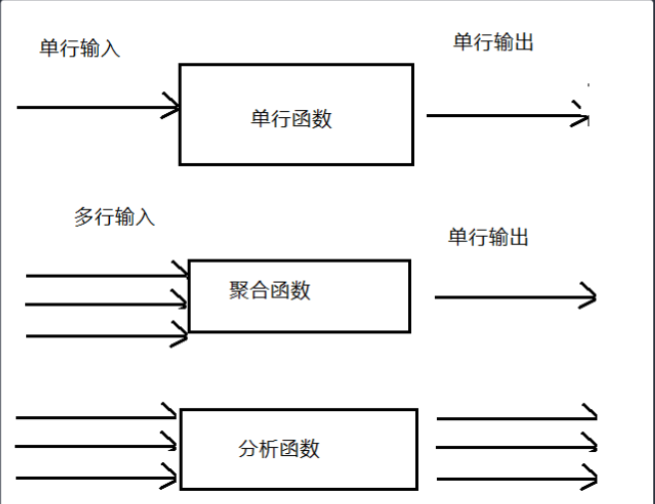
- 单行函数:常用系统函数 字符串,数学,日期时间相关
- 聚合函数 – 共有5个
- sum()求和
- avg()平均值
- max()最大值
- min()最小值
- count()计数
关于聚合函数的注意事项: (1) sum,avg只能用于数值型的列 (2) max,min,count不限类型 (3) 只有count可以使用*作为参数 ,表示将表中的一行作为一个计数单位 (4) 所有的聚合函数都忽略空值 ,如果不想空值被忽略,可以使用ifnull()空值处理函数
10.3 分组查询
(1)group by 分组
- 语法:
select 字段列表....
from 表名
where 条件
group by 子句 -- 指定分组的列
分组的含义: 将指定分组的列中相同的值逻辑上划分为一个组
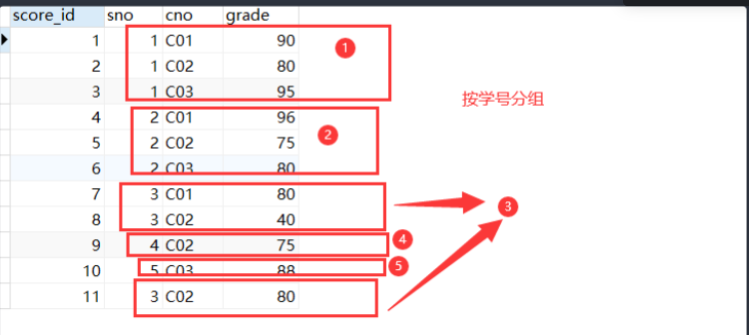
- 示例
-- 参加了选修的学生学号
select sno
from score
group by sno
-- 分组+聚合 一起使用
-- 统计每个学生所选修课程的总分,平均分,及选修的科目数
-- select子句同时出现 非聚合函数列与聚合函数列
-- 必须 将所有的非聚合列放在group by 子句中
select sno 学号,sum(grade) 总分,avg(grade) 平均分 ,count(*) 科目数
from score
group by sno
-- 按课程号分组统计总分
select cno,sum(grade)
from score
group by cno
-- 按性别统计人数
select ssex 性别,count(*) 人数
from student
group by ssex
注:
group up 后面最好加上所有的非聚合列名
(2)having 子句
- 当需要分组后再进行聚合函数的条件判断时,则使用having子句
where -> group by --> having
示例:
-- 需求: 查询统计参加了补考的学生学号,课程号
select sno,cno
from score
-- where count(*)>1 -- where 表中原始数据的筛选 不能是聚合函数列的条件
group by sno,cno
having count(*)>1 -- having 分组后的数据筛选 聚合函数的条件判断
有group by子句时,不一定有having 但是,有having时,一定要先group by **
10.4限制行查询
- 语法:
select 列...
from 表
limit [m,] n -- [放在SQL中所有子句的最后]
对查询结果限制
m - 表示起始行的索引号 [行的索引 从0开始]
n - 限制的记录数 [从1开始计]
- 示例:
-- 查询前3行
select * from score limit 3
-- 等价写法
select * from score limit 0,3
-- Limit实现分页查询SQL:
-- 提供两个参数: 当前页码pno ,每页的记录数 pageSize
select * from score limit 起始索引号startIndex,pageSize
-- 起始索引号startIndex = (pno-1)*pageSize
-- 例如,查看每页3条的第3页的数据
select * from score limit 6,3
--------------------------------- 查询成绩前3名的选修记录
-- order by +limit 配合
select *
from score
order by grade desc
limit 3
— Limit实现分页查询SQL: — 提供两个参数: 当前页码pno ,每页的记录数 pageSize select * from score limit pageSize*(pno-1),pageSize
10.5查询语句的完整子句语法
select 列,sum,avg.count(),max(),min()...
from 表 --- >> 从数据库查找整个表数据,读入到内存中
[where 条件] -- 源数据条件筛选
[group by] -- 分组 --- select
[having] -- 聚合函数的条件筛选
[order by ]
[limit [m,] n]

11.DQL-高阶查询
11.1 多表查询原理
笛卡尔积:
|- 笛卡尔积是数学和数据库领域的基本概念,指两个集合中所有可能有序对的组合
{a,b,c} x {1,2} = {{a,1},{a,2},{b,1},{b,2},{c,1},{c,2}}
11.2 内/等值连接查询
(1)内/等值连接 — 92标准
1.等值连接 92标准
select score.sno,sname,ssex,sage,cno,grade
from student,score
where student.sno=score.sno
2.另一种写法,为表名起别名
select sc.sno,sname,cno,grade
from student as s ,score as sc
where s.sno=sc.sno
3.三表连接
select score.sno 学号,sname 姓名,score.cno 课程号,cname 课程名,grade 成绩
from student,score,course
where student.sno = score.sno and score.cno=course.cno
(2)内/等值连接 — 99标准
等值连接 SQL 99标准
比SQL92标准执行效率高
-- inner join 内连接
select sc.sno,sname,cno,grade
from student as s inner join score as sc on s.sno=sc.sno
三表连接 SQL99标准写法
select sc.sno 学号,s.sname 姓名,sc.cno 课程号,c.cname 课程名,sc.grade 成绩
from student as s inner join score sc on s.sno = sc.sno
inner join course c on sc.cno=c.cno
11.3 外连接查询
注意:
外连接数据是在内连接数据的基础上进行的补充!!!
分为左外连接与右外连接 — left outer join — right outer join
- 左外连接
-- 需求: 查询学生的选修记录,要求格式: 学号,姓名,课程号,成绩
-- 另外,没有参加选修的学生学号及姓名也显示,对应课程号和成绩栏显示null
-- left join 左边的表中有数据,右边表中没有的数据也显示,对应栏为NULL
select s.sno as 学号,s.sname as 姓名,sc.cno as 课程号,sc.grade as 成绩
from student as s left join score as sc on s.sno=sc.sno
order by s.sno
左边表的数据补充右边表没有的数据
- 右外连接
-- right join
select s.sno as 学号,s.sname as 姓名,sc.cno as 课程号,sc.grade as 成绩
from score as sc right join student as s on s.sno=sc.sno
order by s.sno
右边表的数据补充左边表没有的数据
- 案例: 查询出没有参加选修的学生学号,姓名,性别,年龄
select s.sno as 学号,s.sname as 姓名,s.ssex 性别,s.sage 年龄
from student as s left join score as sc on s.sno=sc.sno
where sc.grade is null
11.4 综合示例-多表+分组+聚合
需求: 学号/姓名/总分/平均分
-- step1: 学号/总分/平均分
select sno 学号, sum(grade) 总分,avg(grade) 平均分
from score
group by sno
-- step2: 学号/姓名/总分/平均分
select sc.sno 学号,s.sname 姓名,sum(grade) 总分,avg(grade) 平均分
from score as sc inner join student as s on sc.sno=s.sno
group by sc.sno,s.sname
11.3 case-when子句查询
CASE WHEN子句用于根据条件进行条件判断,并返回相应的结果
(1)语法1:等值条件判断
case 列 when 值1 then 表达式1
when 值2 then 表达式2
...
[else 表达式N] -- 以上的when值都不能满足列的条件,则执行else部份
-- 如果没有else子句,以上条件都不满足时,则最终结果为 NULL
end -- end不能掉,否则语法错误
- 示例
select score_id,sno,cno,
case cno when 'C01' then '课程一'
when 'C02' then '课程二'
else '课程三'
end as "课程描述", grade
from score
(2)语法2: 区间范围的条件判断
case when 列>=值1 then 表达式1
when 列>=值2 then 表达式2
...
[else 表达式N] -- 以上的when值都不能满足列的条件,则执行else部份
-- 如果没有else子句,以上条件都不满足时,则最终结果为 NULL
end -- end不能掉,否则语法错误 414475
- 示例
select score_id,sno,cno, grade,
case when grade>=90 then '优'
when grade>=80 then '良'
when grade>=70 then '中'
when grade>=60 then '及格'
else '不及格'
end as 成绩等级
from score
11.4 子查询
- 概念
子查询-subquery 又称为"嵌套查询" 意味着在一个父查询中的某个子句部份还有其他的查询(称为"子查询")
可以用来替代绝大部份的连接查询
执行顺序: 先执行子查询,将查询的结果返回给父查询,再执行父查询得到最终的结果
子查询语法上必须使用()
- 子查询的语法形式
select
(子查询) -- 只能是单行单列的结果
from
(子查询) -- 必须要有查询结果,类型不限: 单行单列,多行单列,多行多列
where
(子查询)
|-条件使用关系运算符: >,>=,<,<=,=,<> -- 子查询只能是单行单列
|-条件使用in,not in -- 子查询可以是单行单列,多行单列
having
聚合函数 >,<,>=,....in,not in (子查询) --与where相同
#DML语句中子查询形式:
insert into 表(列,...) values((子查询),(子查询),(子查询)...)
update 表 set 列= (子查询) where (子查询)
delete from 表 where (子查询)
- 示例
# select 部份子查询 只能是单行单列
-- 需求1:查询学生成绩表中成绩占所有选修成绩的占比
select * from score
select sum(grade) from score
select score_id 序号,sno 学号 ,cno 课程号,grade 成绩,
concat(round(100*grade/(select sum(grade) from score),2),'%') as "占比%"
from score
# from 子查询 只需要有查询的结果的子查询
# 要求:子查询必须指定别名
select a.姓名,b.cno,b.grade
from
(select sno 学号,sname 姓名 from student) as a,
(select sno 学号,cno,grade from score) as b
where a.学号=b.学号
-- 需求2: 学生成绩表中每个等级的人数
等级 人数
--------------------
优 5
良 2
中 1
及级 3
差 4
select 成绩等级,count(*) 人数
from (
select score_id,sno,cno,grade,
case when grade>=90 then '01-优'
when grade>=80 then '02-良'
when grade>=70 then '03-中'
when grade>=60 then '04-及格'
else '05-不及格'
end as 成绩等级
from score
) as a
group by 成绩等级
order by 成绩等级
-- 需求3: 选修了C01号课程的成绩比选修了C02号课程的成绩高的学号及姓名
select sno 学号,sname 姓名
from student
where sno in (
select a.sno
from
(select sno,grade from score where cno='C01') as a,-- 查询选修了C01课程的学号及成绩
(select sno,grade from score where cno='C02') as b -- 查询选修了C02课程的学号及成绩
where a.sno=b.sno and a.grade>b.grade
)
-- 另一种写法
select a.sno 学号,c.sname 姓名
from (select sno,grade from score where cno='C01') as a,-- 查询选修了C01课程的学号及成绩
(select sno,grade from score where cno='C02') as b, -- 查询选修了C02课程的学号及成绩
student as c
where a.sno=b.sno and a.grade>b.grade and a.sno=c.sno
# where子查询
-- 关系判断>,>=,<,<=,=,<> 只能是单行单列
-- 谓词in,not in 可以是多行单列
-- 需求4: 查询学生表中年龄高于所有学生的平均年龄的学生
select avg(sage) from student
select *
from student
where sage > (select avg(sage) from student)
-- 需求5: 查询只选修了一门课的学生学号及姓名
select sno 学号,sname 姓名
from student
where sno in (
select sno -- 子查询:查出只选修了一门课的学号
from score
group by sno
having count(*)=1
)
-- 删除黄晓倩的选修记录
delete from score where sno in (select sno from student where sname='黄晓倩')
需求3: 选修了C01号课程的成绩比选修了C02号课程的成绩高的学号及姓名
select sno 学号,sname 姓名
from student
where sno in (
select a.sno
from
(select sno,grade from score where cno='C01') as a,-- 查询选修了C01课程的学号及成绩
(select sno,grade from score where cno='C02') as b -- 查询选修了C02课程的学号及成绩
where a.sno=b.sno and a.grade>b.grade
)
12.MySQL补充
12.1 视图 – View
- 简介
视图 - 是一张"虚表",是存储的select查询语句
作用与特点: 简化数据的访问,隐藏原始的数据表,提升数据安全性
工作原理:
视图本身不存储数据,而是基于一个或多个基表(实际存储数据的表)生成。当访问视图时,数据库系统会自动执行定义视图的查询,并返回结果集。
- 创建视图
-- 创建视图
create view v_stu as select sno,sname,ssex,sage from student where classid='J001'
-- 访问视图
select * from v_stu
-- 创建用户
create user 'zhangsan'@'localhost' IDENTIFIED by '123'
-- 为用户zhangsan授权room表的所有权限
GRANT all ON woniu79.room TO 'zhangsan'@'localhost'
-- 授予视图v_stu的访问select权限
GRANT select ON woniu79.v_stu TO 'zhangsan'@'localhost'
-- 撤回权限
revoke select on woniu79.v_stu from 'zhangsan'@'localhost'
12.2 索引 – Index
- 简介
索引 -数据库中一种对象,与表单独存储,内容基于表而创建的,如果表被删除,基于该表的所有的索引都会自动删除
类似一本书的目录,新华字典
索引优点: 提高查询的速度
索引缺点: 占用存储空间,DML操作表时,降低了速度
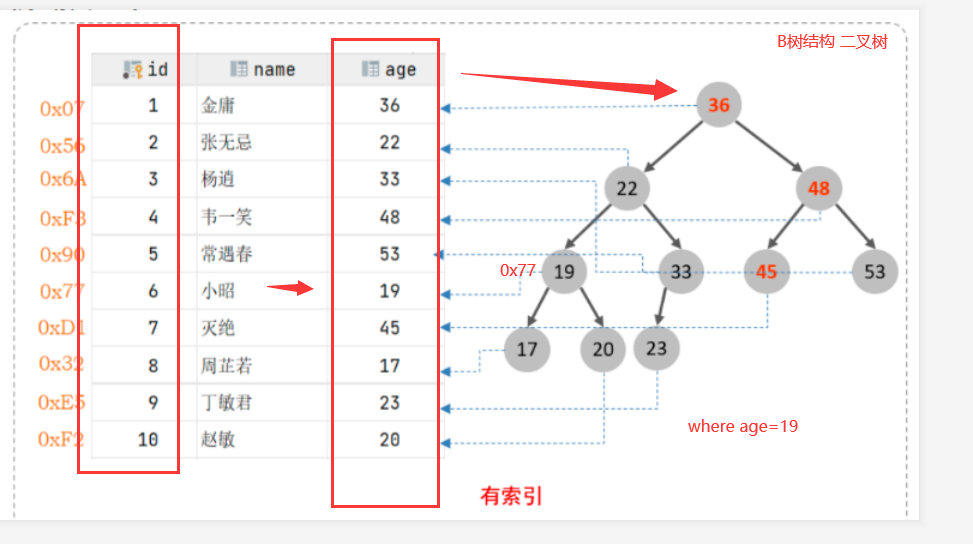
- 索引的分类
(1) 普通索引 - [B树] -- 外键
(2) 唯一索引 - [B树-unique 索引列的值不能重复]
(3) 主键索引 - 属于唯一索引中的特例
(4) 组合索引 - 基于多个列来共同创建索引,where中涉及到组合索引中的列时,提高查询速度
- 索引的相关SQL
-- 查看某个表上的索引
show index from student
-- 创建索引
create index idx_age on student(sage)
-- 删除索引
drop index idx_age on student
- 索引测试
-- 创建app_user测试表
CREATE TABLE `app_user`
(
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) DEFAULT '' COMMENT '昵称',
`email` VARCHAR(50) DEFAULT NULL COMMENT "邮箱",
`phone` VARCHAR(20) DEFAULT NULL COMMENT "手机号",
`gender` TINYINT(4) DEFAULT NULL COMMENT "性别 0-男, 1-女",
`password` VARCHAR(100) NOT NULL COMMENT "密码",
`age` TINYINT(4) NOT NULL COMMENT "年龄",
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY(`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 COMMENT='app用户表';
-- 插入百万数据
DELIMITER $$
CREATE FUNCTION mock_data()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 2000000;
DECLARE i INT DEFAULT 0;
WHILE i < num DO
-- 插入语句
INSERT INTO `app_user`(`name`,`email`,`phone`,`gender`,`password`,`age`)
VALUES (CONCAT('用户',i),'123456@qq.com', CONCAT('18', FLOOR(RAND()*((999999999-100000000)+100000000))), FLOOR(RAND()*2), UUID(), FLOOR(RAND()*100));
SET i = i+1;
END WHILE;
RETURN i;
END;
-- 执行可能会出现This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary报错。
-- 如果出现,可以先执行set global log_bin_trust_function_creators=TRUE ,然后再试下。
set global log_bin_trust_function_creators=TRUE
-- 执行函数 向表中添加200万行数据
select mock_data();
------------------------------------
-- 查看表上的索引
show index from app_user
-- 为phone列创建索引
create index idx_phone on app_user(phone)
-- 删除表上的idx_phone索引
drop index idx_phone on app_user
-- 测试查询
select * from app_user where phone='18536853057'
