shell
1.shell概述
1、shell概述
1.1 shell特点
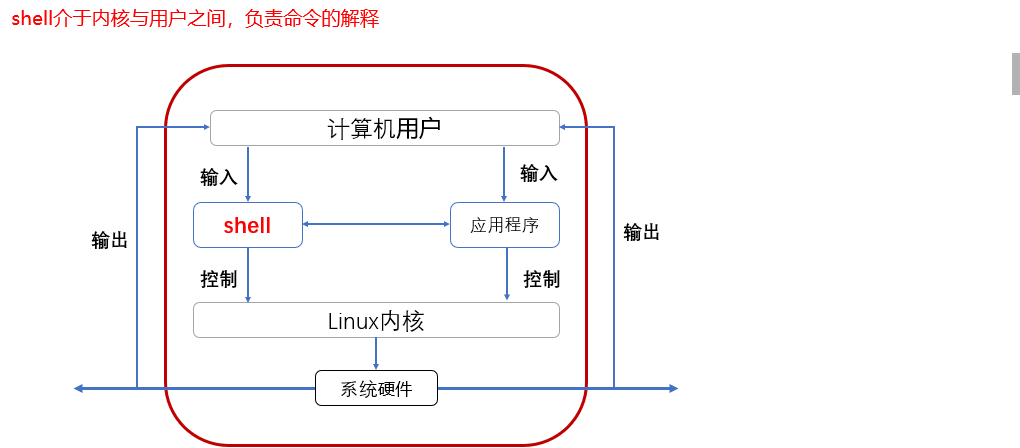
是人机交互的接口。
- 非图形化直接控制系统
- 自动化运维
- 容器和云原生
1.2 编程语言分类
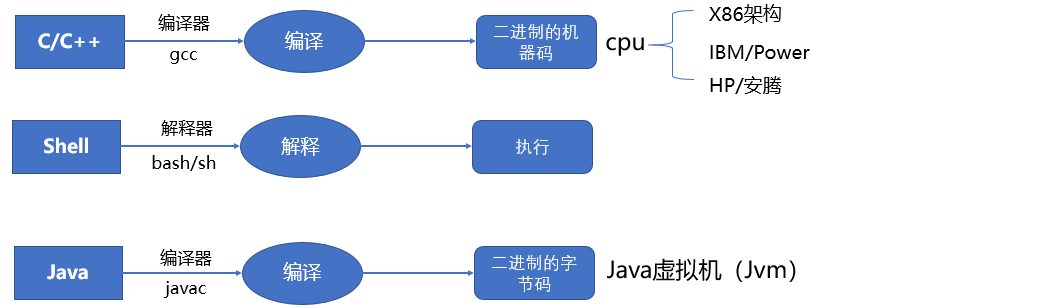
编程语言总体上分类两类:编译型语言,解释型语言
- 编译型语言:程序在执行之前需要一个专门的编译过程==,把程序编译成为机器语言文件,运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。如C、C++、java
- 解释型语言:程序不需要编译,程序在运行时由解释器翻译成机器语言,每执行一次都要翻译一次。因此效率比较低。比如Python/JavaScript/ Perl /ruby/Shell等都是解释型语言
执行流程:
- 编译型语言:源代码 → 编译器(Compiler)→ 机器码(二进制文件)→ 直接执行
- 解释型语言:源代码 → 解释器(Interpreter)→ 逐行解释执行
1.3 shell脚本基础
-
概述
Shell是指操作系统的用户界面,提供了一种与内核进行交互的方式,也被称为命令解释器。Shell可以让用户通过命令行或脚本来启动、挂起、停止等操作系统级别的程序,也能够进行文件操作、文本处理、调用其他程序等多种操作。通常情况下,Shell是由C语言编写的应用程序,它和命令行交互、解释命令并执行相应的操作。
Shell通常包含两个部分:命令提示符和命令行解释器。
- 命令提示符是Shell给出的提示,例如”$“、”%”等,用于提示用户可以输入命令了。
- 命令行解释器则负责读取用户输入的命令,并且将其转换为可执行的操作系统命令。

shell就是人机交互的一个桥梁
-
分类
/bin/sh #是bash shell的一个快捷方式 /bin/bash #bash shell是大多数Linux默认的shell,包含的功能几乎可以涵盖shell所有的功能 /sbin/nologin #表示非交互,不能登录操作系统 /bin/dash #小巧,高效,功能相比少一些 /bin/tcsh #是csh的增强版,完全兼容csh /bin/csh #具有C语言风格的一种shell,具有许多特性,但也有一些缺陷查看当前shell:
[root@localhost ~]# echo $SHELL /bin/bash


四个问题:
1、查看系统支持的shell
cat /etc/shells
2、怎么进入其他的shell
csh
3、怎么退出当前shell
exit
4、如何查看当前使用的shell是什么shell
echo $SHELL
ps -p $$- 格式
shell脚本就是说我们把原来 linux 命令或语句放在一个文件中,然后通过这个程序文件去执行时,我们就说这个程序为 shell 脚本或 shell 程序;我们可以在脚本中输入一系统的命令以及相关的语法语句组合,比如变量,流程控制语句等,把他们有机结合起来就形成了一个功能强大的shell 脚本

1.4 运行方式(重点)
1)标准运行
前提:用户对文件要具有可执行权限
chmod a+x first.sh
运行分为绝对路径和相对路径

2)非标准运行
shell脚本没有可执行权限的情况下
bash print_date.sh
bash -x print_date.sh
-x:一般用于排错,查看脚本的执行过程
-n:用来查看脚本的语法是否有问题
sh print_date.sh
source print_date.sh
. print_date.sh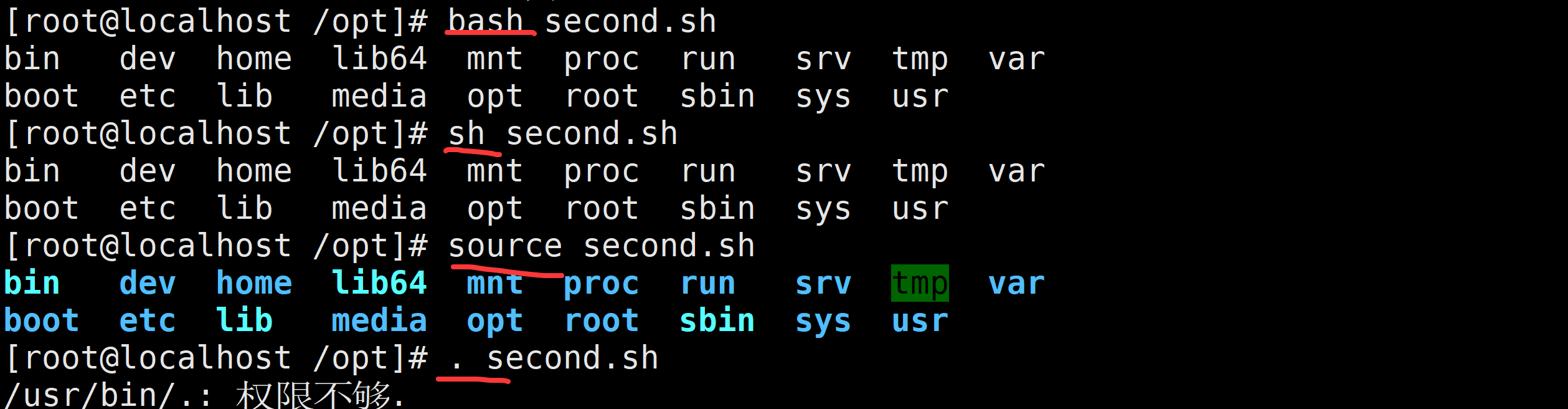
在 Bash 中,source(或简写为.)命令用于在当前 Shell 环境中执行脚本,与直接运行脚本(如bash script.sh)有本质区别。
bash:新建子 Shell 进程,脚本中的变量仅限于子 Shell,仅修改子 Shell 的环境变量。
source:直接在当前 Shell 进程中执行脚本,而非创建子 Shell。脚本中定义的变量、函数、环境变量等会直接生效于当前环境。2、bash基本特性(掌握)
2.1 命令和文件自动补全
执行命令跟使用tab键实现自动补全功能
2.2 常见的快捷键
ctrl + c # 终止前台运行的程序
ctrl + z # 将前台运行的程序挂起到后台
ctrl + d # 退出 等价exit
ctrl + l # 清屏
ctrl + a # 光标移到命令行的最前端
ctrl + e # 光标移到命令行的后端
ctrl + u # 删除光标前所有字符
ctrl + k # 删除光标后所有字符
ctrl + r # 搜索历史命令
jobs查看后台程序的编号,fg 1 根据编号恢复程序到前台执行

2.3 常用的通配符
通配符主要是用于查找,匹配的场景,有了通配符往往会提高我们的查询效率,常用的通配符有:
*: 匹配0或多个任意字符
?: 匹配任意单个字符
[list]: 匹配[list]中的任意单个字符
[!list]: 匹配除list中的任意单个字符
{string1,string2,...}: 匹配string1,string2或更多字符串前提:切换到root账号家目录,清除所有内容,创建一下文件:touch file{1..3} touch file{1..13}.jpg
- 星号 匹配0或多个任意字符

- ? 匹配任意当个字符

-
[6-9] 匹配一定范围的单个字符

2.4 引号
- 双引号”” : 会把引号的内容当成整体来看待,允许通过$符号引用其他变量值
- 单引号’’ : 会把引号的内容当成整体来看待,禁止引用其他变量值,shell中特殊符号都被视为普通字符
- 反撇号“ : 反撇号和$()一样,引号或括号里的命令会优先执行,如果存在嵌套,反撇号不能用
$(command)用于命令替换,它执行命令并将输出用作其他命令或变量的值双引号: “” 看做一个整体,可以执行命令 $()
单引号: ‘’ 看做一个整体,不可以执行命令
反撇号:“ 效果跟$()一样,用于执行命令、


3、变量分类(重点)
3.1 概述
变量:变量指的是系统中可改变的量
定义:使用=连接,=两边不能有空格。例如:name=zhangsan num=5 java=/usr/local/java
变量名=变量值分类:
- 本地变量:当前用户自定义的变量。当前进程中有效,其他进程及当前进程的子进程无效,其它用户也无效
- 环境变量:当前进程有效,并且能够被子进程调用,其它进程无效,其它用户无效
- 查看当前用户的环境变量:env
- 查询当前用户的所有变量(临时变量与环境变量) :set
- 将当前变量变成环境变量:export
- 系统变量(内置bash中变量) : shell本身已经固定好了它的名字和作用
3.2 本地变量
当前用户自定义的变量。当前进程中有效,其他进程及当前进程的子进程无效,其它用户也无效

3.3 环境变量
当前进程有效,并且能够被子进程调用,其它进程无效,其它用户无效
使用export命令可以将本地变量转化为环境变量

查看变量(env,set)
- env – 环境变量
- set – 全部变量


3.4 系统变量
shell本身已经固定好了它的名字和作用

特殊变量
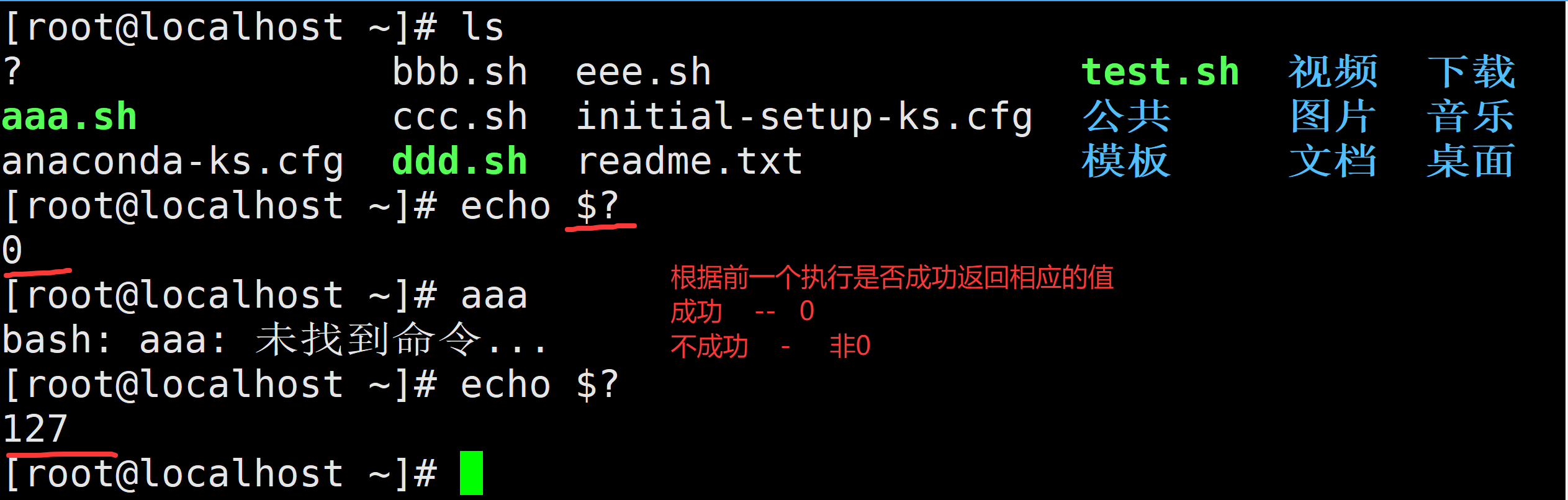
$?(重要):上一条命令执行后返回的状态,当返回状态值为0时表示执行正常,非0值表示执行异常或出错
若退出状态值为0,表示命令运行成功
若退出状态值为127,表示command not found
若退出状态值为126,表示找到了该命令但无法执行(权限不够)
若退出状态值为1&2,表示没有那个文件或目录
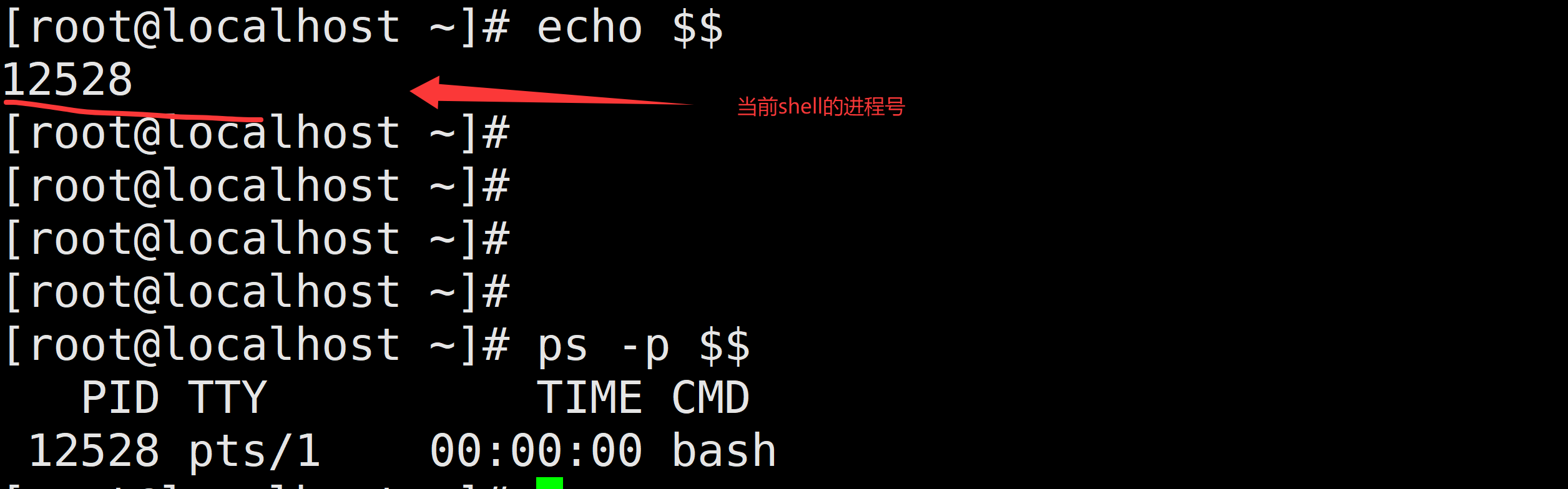
$$:当前所在进程的进程号
$!:后台运行的最后一个进程号 (当前终端)
!$ 调用最后一条命令历史中的参数
!! 调用最后一条命令历史
(重要)
$#:脚本后面接的参数的个数
$*:脚本后面所有参数,参数当成一个整体输出,每一个变量参数之间以空格隔开
$@: 脚本后面所有参数,参数是独立的,也是全部输出
(重要)
$0:当前执行的进程/程序名
$1~$9 位置参数变量
${10}~${n} 扩展位置参数变量 第10个位置变量必须用{}大括号括起来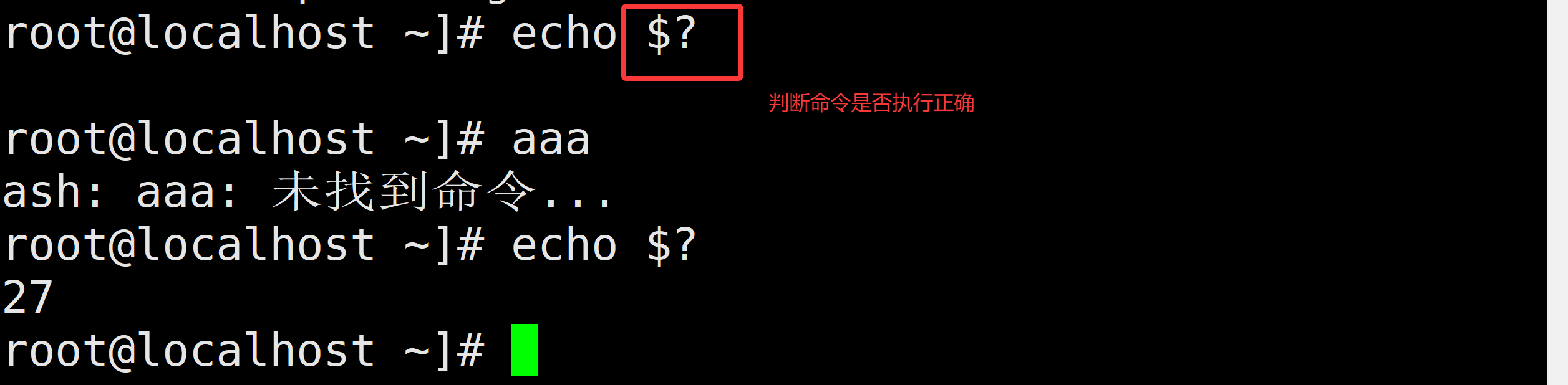

3.5 环境变量文件
环境变量可以理解为全局变量,所谓全局,就是对更大范围的访问生效
$HOME : 指的是当前用户的家目录
$HOME/.bashrc # 当前用户的bash信息(aliase、umask等)$HOME/.bash_profile # 当前用户的环境变量()
/etc/bashrc # 使用bash,shell用户全局变量,别名,全局变量
/etc/profile # 系统和每个用户的环境变量信息,安装应用之后需要配置的地方$HOME/.bashrc
Bash shell 的配置脚本,属于用户级配置文件(仅对当前用户生效)。
$HOME/.bash_profile
用户登录时执行的初始化脚本,用于设置环境变量、启动服务等登录相关配置。
/etc/bashrc
定义所有用户的交互式 Bash Shell的默认行为,属于系统级配置。
/etc/profile
定义所有用户登录时执行的环境变量、全局变量和脚本,属于系统级配置。
用户级配置(如~/.bash_profile)中的变量会覆盖/etc/profile中的同名变量。| 特性 | .bash_profile |
.bashrc |
|---|---|---|
| 执行场景 | 登录 Shell(如 SSH、本地终端登录) | 非登录 Shell(如bash启动的子 Shell) |
| 执行次数 | 登录时执行一次 | 每次启动子 Shell 时执行 |
| 典型用途 | 环境变量、系统服务启动 | 别名、函数定义、终端显示优化 |
| 加载顺序 | 先于.bashrc执行 |
通常由.bash_profile调用执行 |
在 Linux 系统中,这四个配置文件的执行顺序取决于 Shell 的启动方式(登录 Shell 或非登录 Shell)以及 变量的定义位置。以下是详细的执行顺序和覆盖规则:
一、执行顺序核心规则
- 登录 Shell(如 SSH 登录、su – user)
/etc/profile → ~/.bash_profile → ~/.bash_login → ~/.profile → ~/.bashrc → /etc/bashrc- 关键点:
- 系统级配置优先:先加载
/etc/profile。 - 用户级配置覆盖:
~/.bash_profile中的变量会覆盖/etc/profile中的同名变量。 .bashrc被间接加载:通常在.bash_profile中会通过source ~/.bashrc引用用户的.bashrc,而.bashrc又会引用/etc/bashrc。
- 系统级配置优先:先加载
- 非登录 Shell(如直接运行 bash 或执行脚本)
~/.bashrc → /etc/bashrc-
关键点:
-
仅加载用户和系统的 bashrc:不执行
/etc/profile和~/.bash_profile。 -
变量覆盖:
~/.bashrc中的变量会覆盖/etc/bashrc中的同名变量。
-
4、变量定义
4.1 变量规则
变量的定义需要遵循一定的规则,如下:
- 默认情况下,shell里定义的变量是不分类型的,可以给变量赋与任何类型的值;
传统编程语言
string -- 字符串 - 姓名 string name=wangxiaolong
int - 整数 -- 数字
boolean -- 布尔值 - 真假- 等号两边不能有空格,对于有空格的字符串做为赋值时,要用引号引起来;变量名=变量值

- 变量名区分大小写

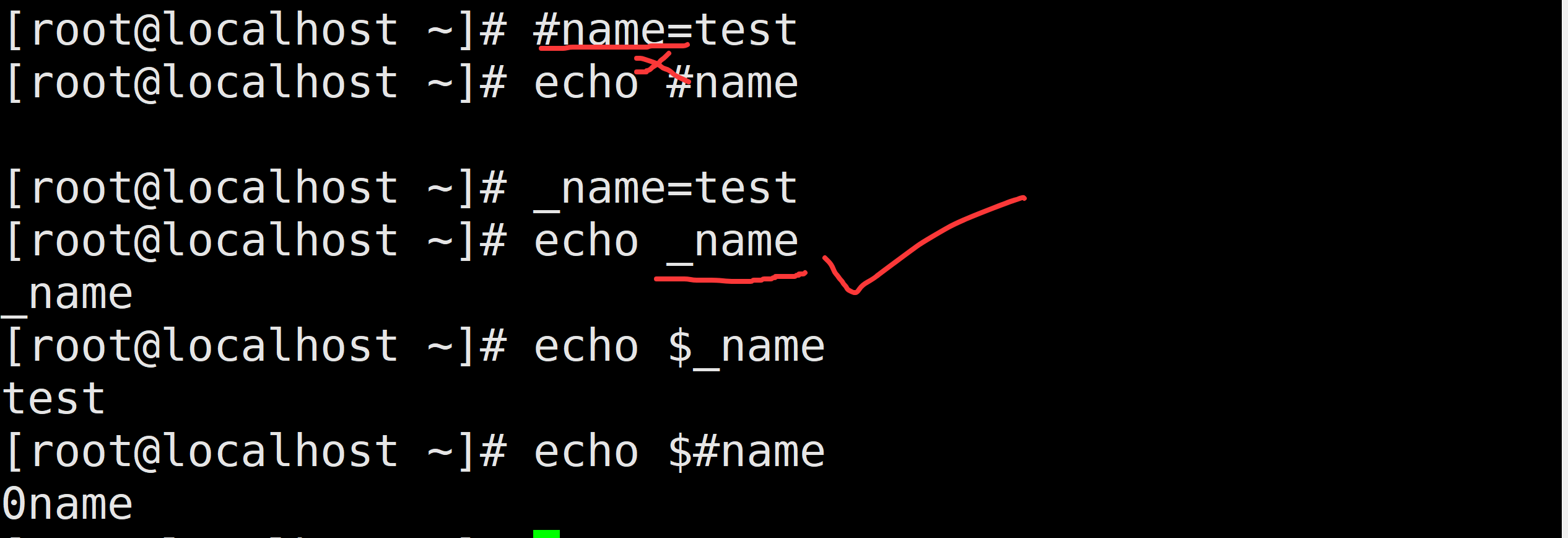
- 变量名可以是字母或数字或下划线,但是不能以数字开头或者特殊字符(下划线开头可以)
- 获取变量:
$变量名或者${变量名}
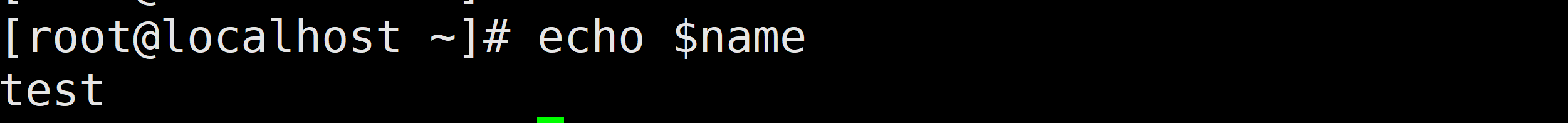
- 取消变量:unset 变量名

- 定义变量是,如果该变量名已经存在,则起到修改的效果

- 可以将命令的执行结果保存到变量中

4.2 变量类型
1)声明变量declare
命令:declare
作用:定义及获取有类型的变量
语法:declare [选项] 变量名=值
选项参数:
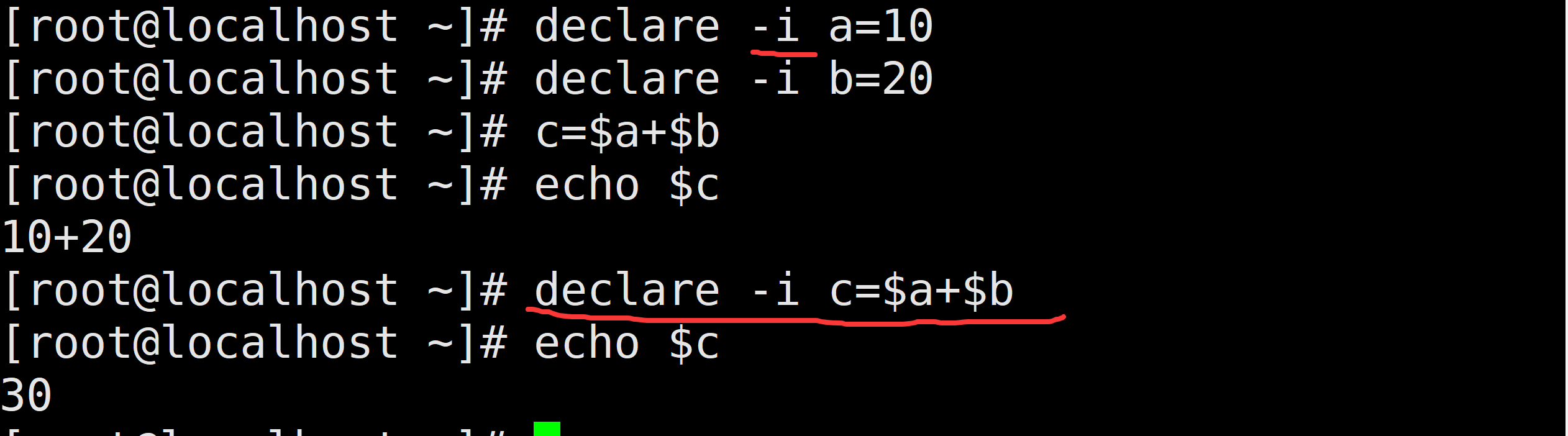
-i:将变量看成整数
-r:使变量只读(readonly)
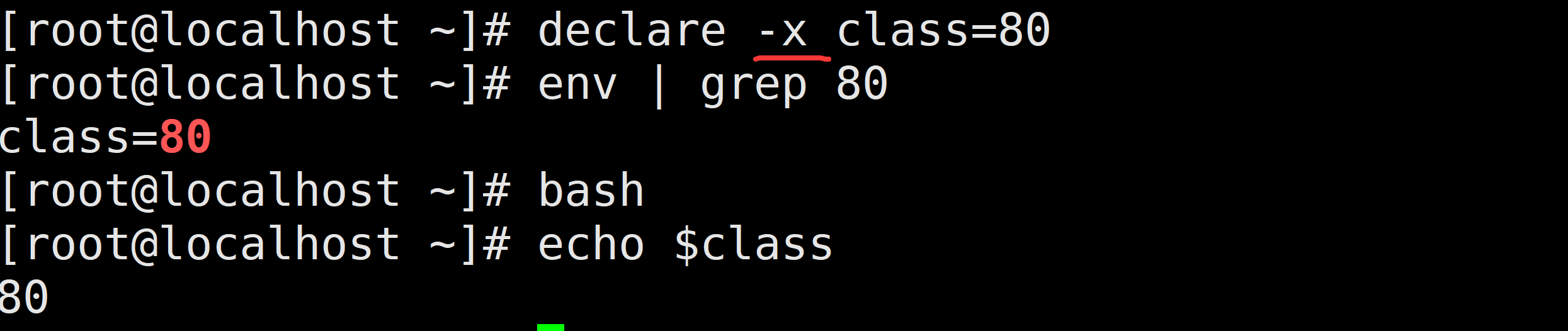
-x:标记变量通过环境导出(export)
-a:指定为索引数组(查看普通数组)
-A:指定为关联数组(查看关联数组)使用declare命令将变量定义成整数
将变量声明为只读,不能修改

将变量声明成环境变量
4.3 普通数组
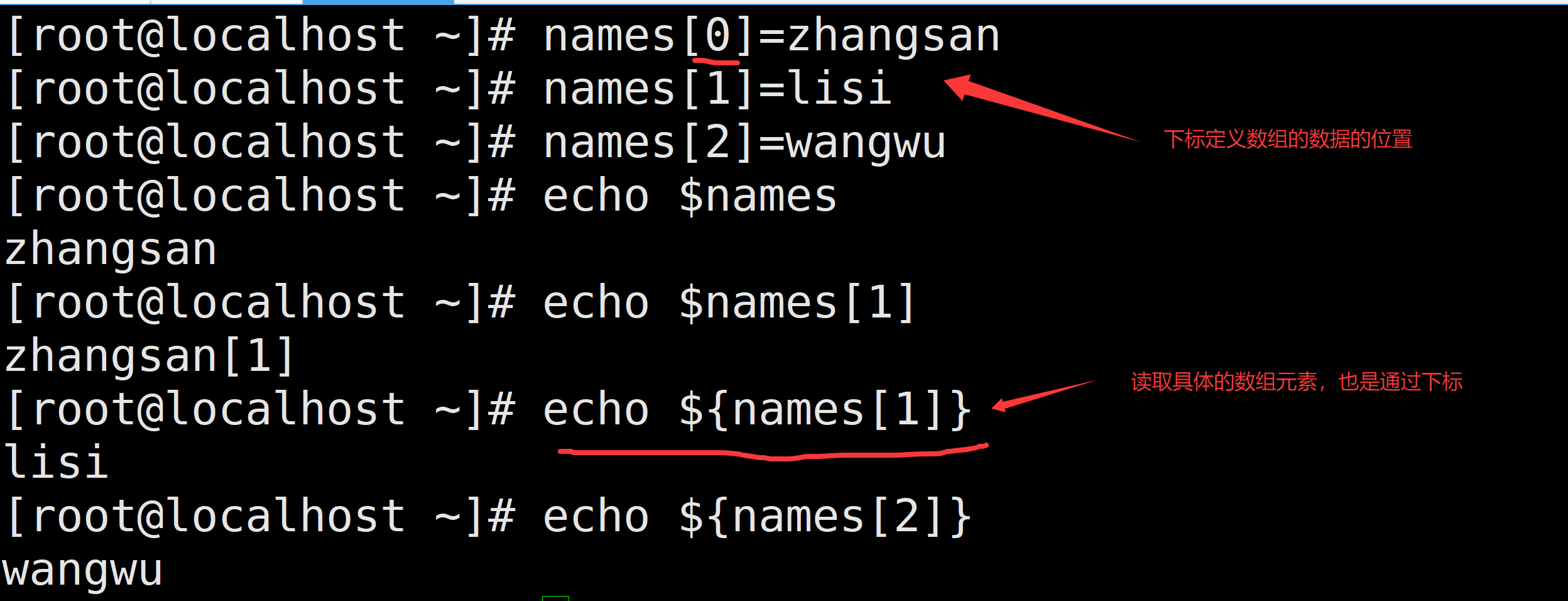
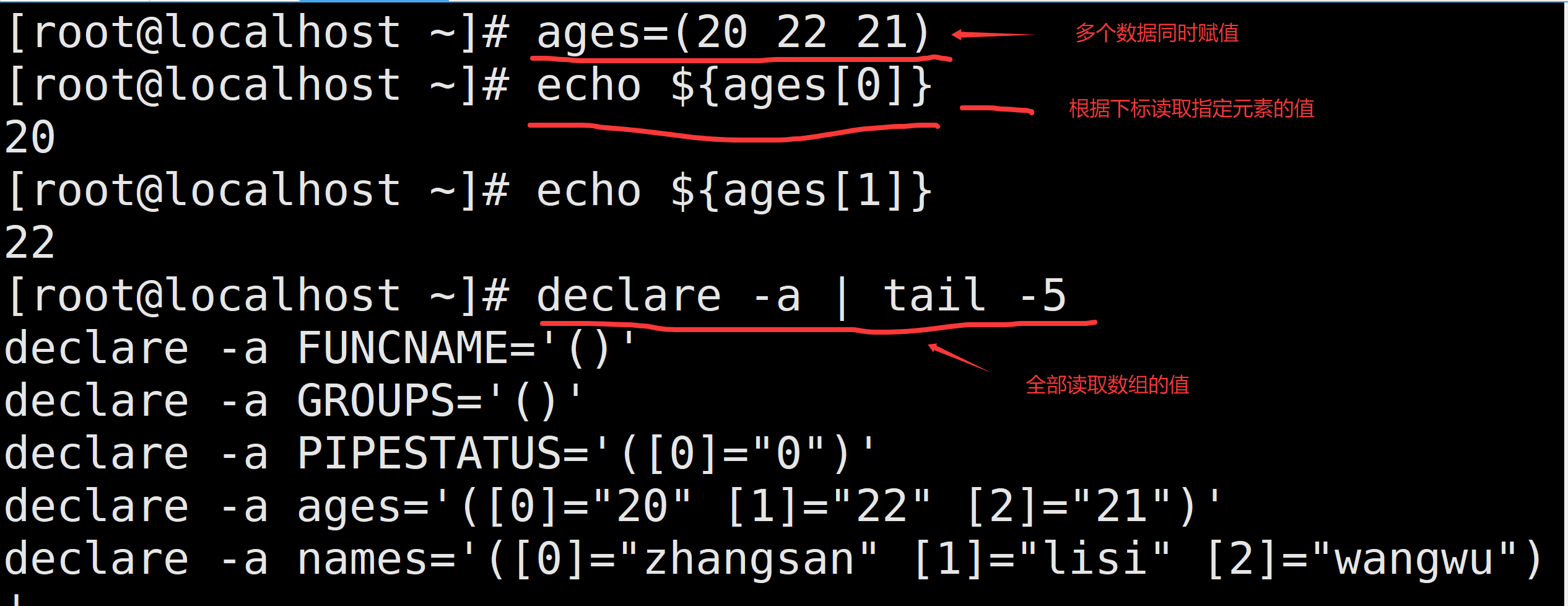
多个数据组合成数组
- 一个一个定义

- 多个元素同时赋值

4.4 关联数组
一个一个数据的创建
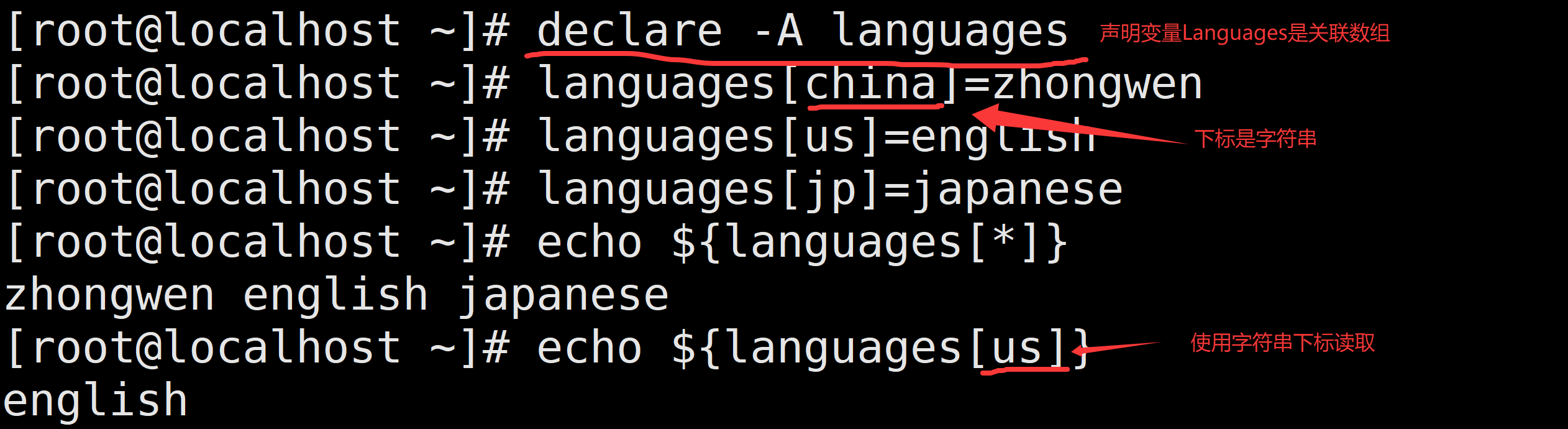
多个数据同时创建
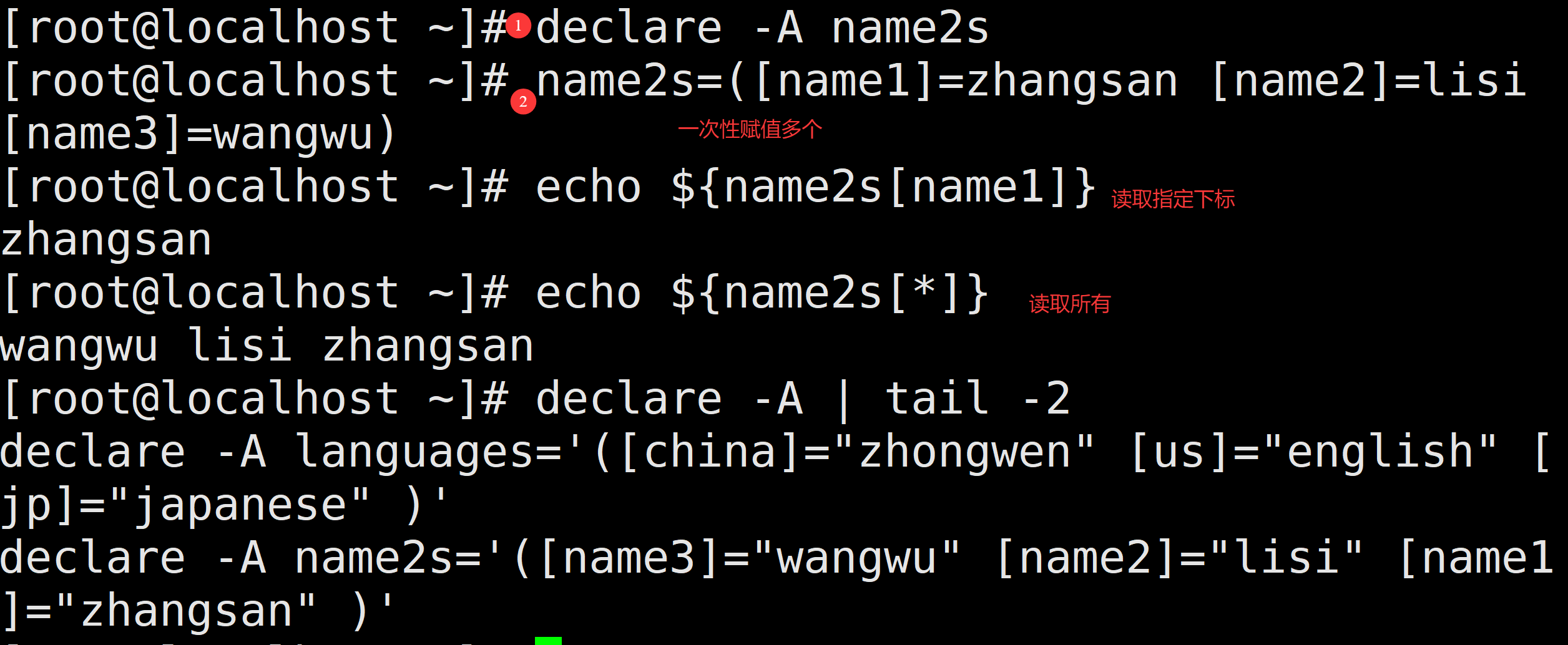
4.5 数组的读取:
${array[string]} # string表示该位置的名称
使用@ 或 * 可以获取数组中的所有元素:
echo ${array[string]} # 获取string位置的内容
echo ${array[*]} # 获取数组里的所有元素
echo ${#array[*]} # 获取数组里所有元素个数
echo ${!array[@]} # 获取数组元素的索引下标
declare -A # 查看所有关联数组信息 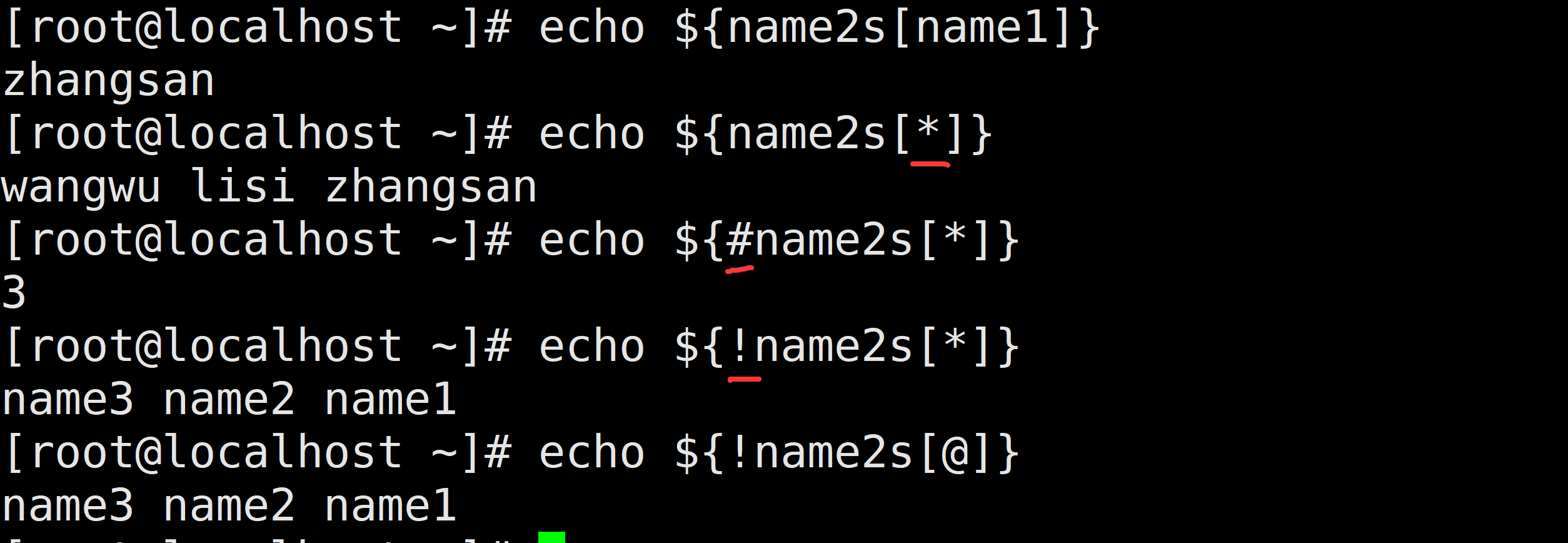
4.6 交互式定义变量(read)
命令:read
作用:主要用于让用户去定义变量值
语法:read [options] [var1 var2]
选项参数:
-p:提示信息
-n:字符数 (限制变量值的字符数)
-s:不显示
-t:超时(默认单位秒)(限制用户输入变量值的超时时间)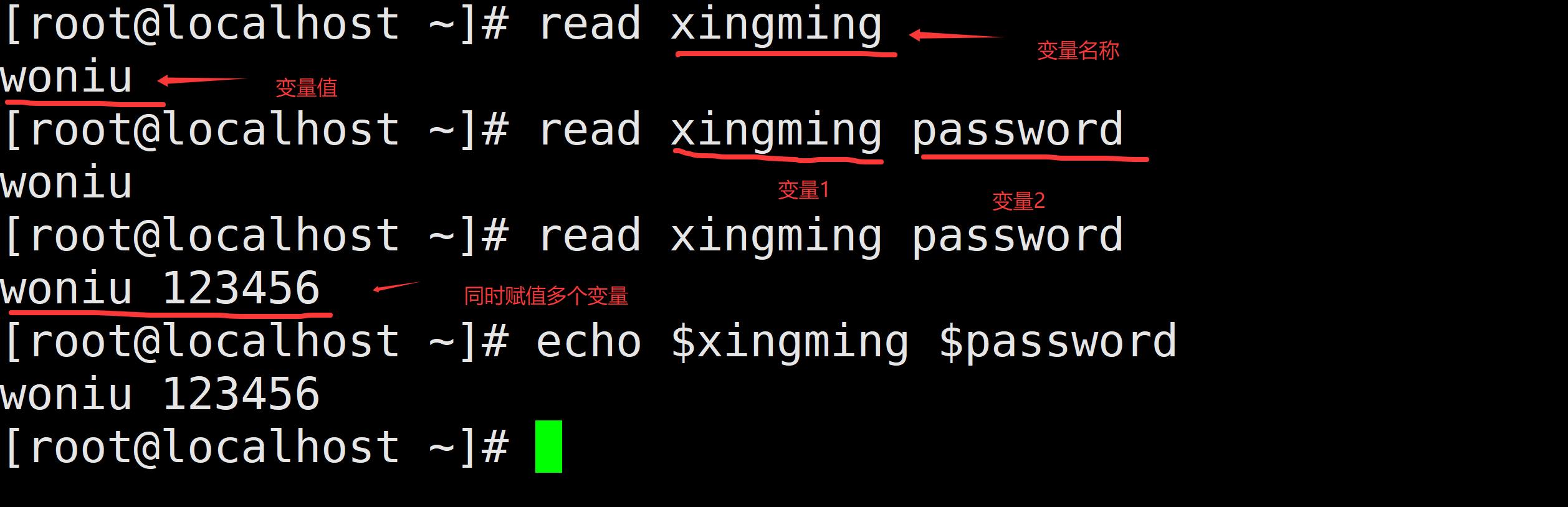

案例:
需求:定义一个变量`r1`,通过交互式进行赋值
read r1
需求:定义两个变量`r2``r3`,通过交互式进行赋值(同时赋值)
read r2 r3
需求:定义一个变量`passwd`,通过交互式进行赋值。提示信息为`input your Passwd:`,并设置不显示用户的输入
read -s -p "input your passwd" passwd
需求:定义一个文件`p.txt`,在文件中中写入两个IP,以空格隔开,将文件中的值赋值给变量`p1``p2`
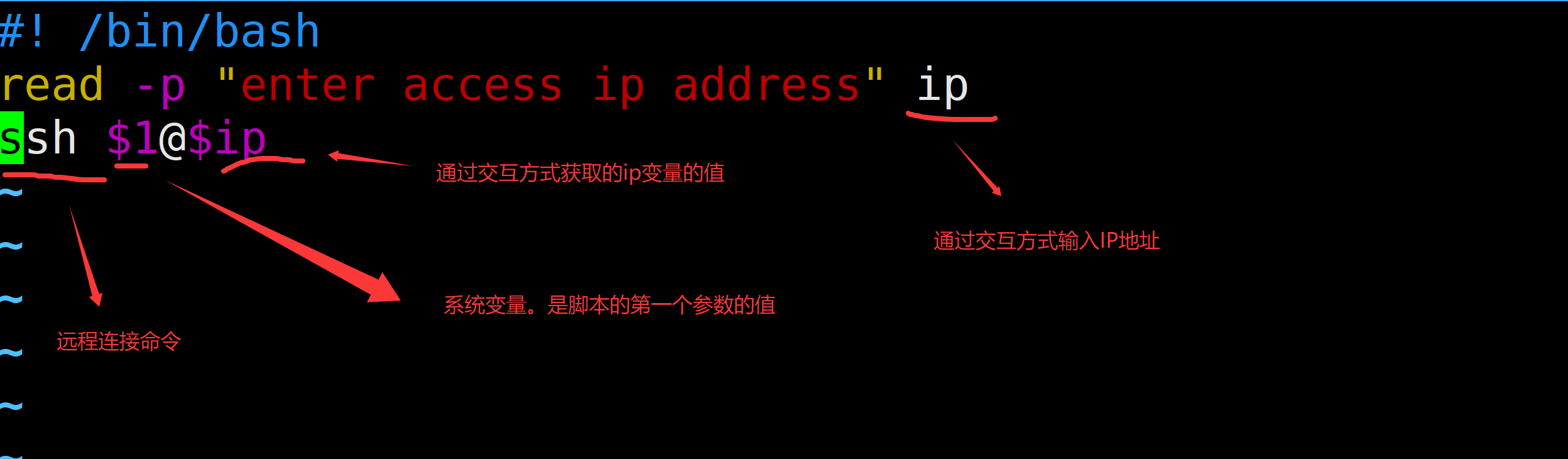
1. 定义一个脚本,ss.sh
2. 从控制台录入一个数据,一个IP
3. 远程连接该主机(账号通过参数的方式传递) ss.sh root
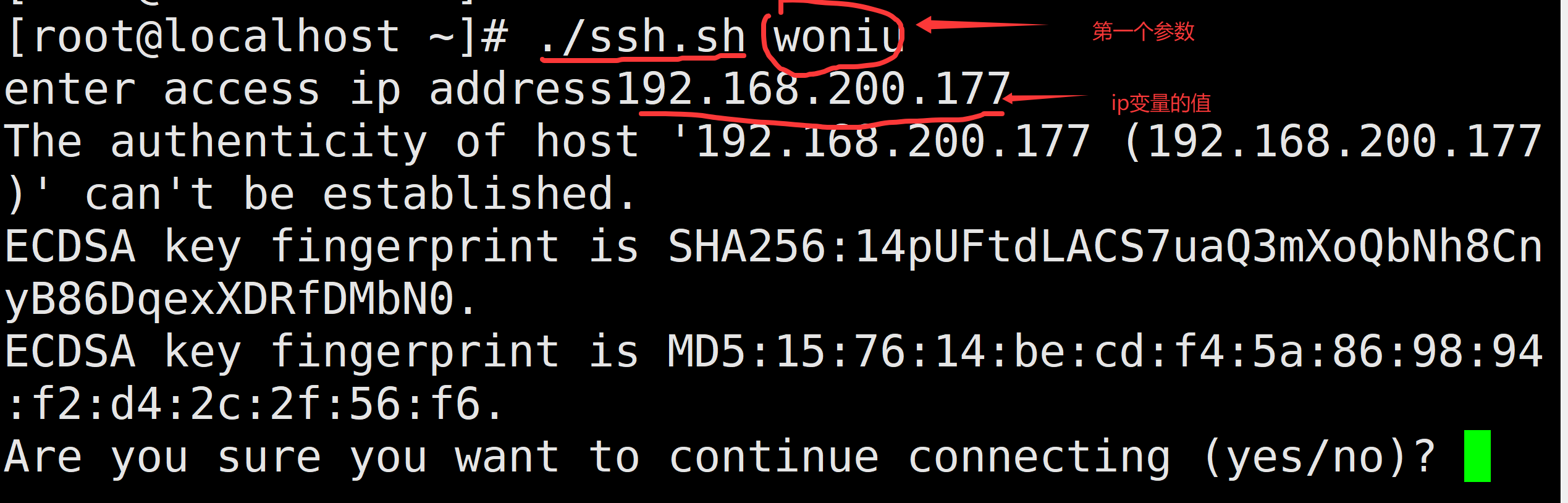
#!/bin/bash
read -p "请输入远程主机的地址:" ip
ssh -p 10086 $1@$ip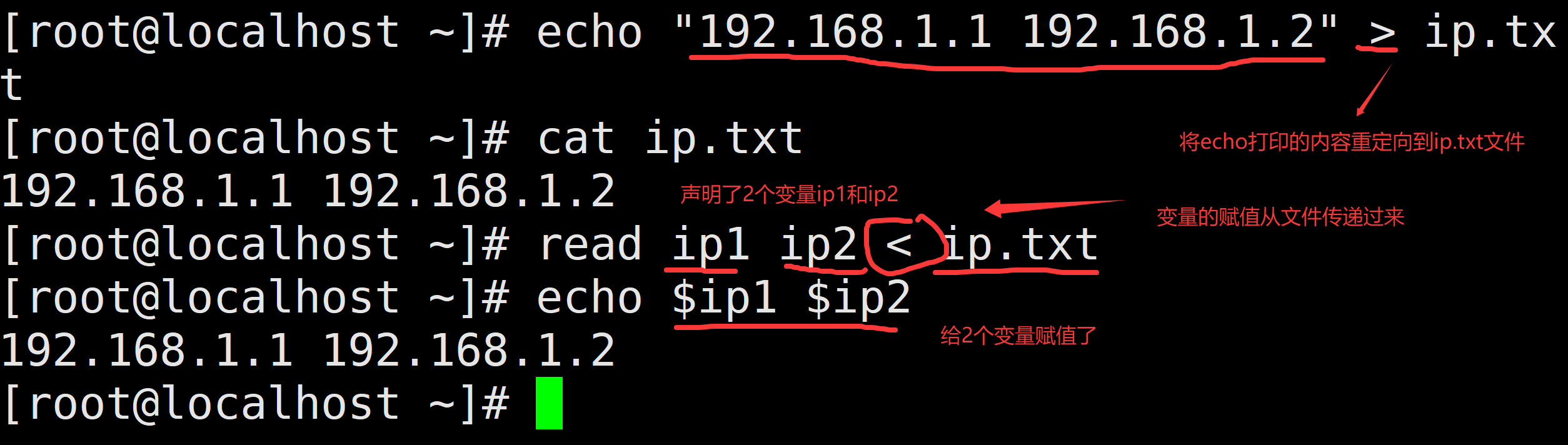
SSH远程连接脚本:
2. 四则运算
1 概述
算术运算:默认情况下,shell就只能支持简单的整数运算,就是数字运行,数字运算支持以下:
+ - * / %(取模,求余数)复杂运算需要借助其他工具(bc)
bc是一个用于计算的命令行工具,可以执行高精度算术运算、逻辑运算、函数操作、数值比较、赋值等操作。bc具有一个交互式环境,也可以从脚本文件中读取命令。在终端中输入bc,就可以进入bc的交互模式。2 运算的方式
Bash shell 的算术运算有四种方式:
- 使用 $(( ))
- 使用$[ ]
- 使用 expr 外部程式
- 使用let 命令
演示:
使用$(())
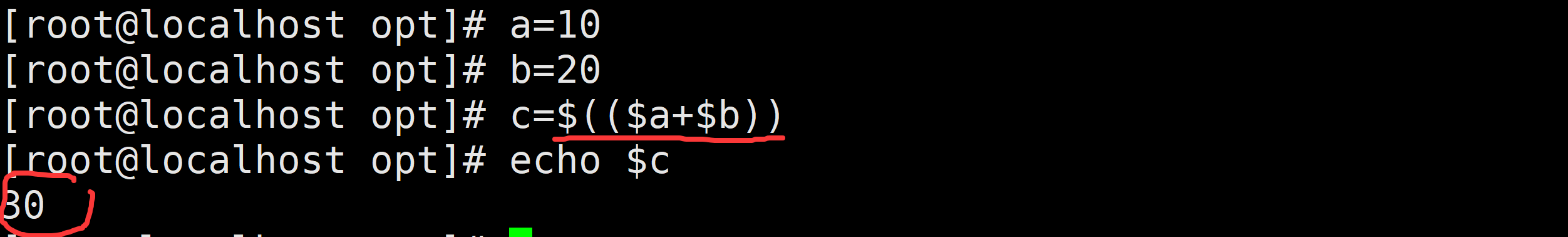
使用$[]
自增

echo $(($a+$b))
这种写法运用了双括号 ((...)) 结构,这是 bash 里专门用于进行算术扩展的结构。其优势在于支持丰富的算术表达式,像 +、-、*、/、% 等运算符都能使用,而且还能处理变量赋值、自增自减等操作。使用时,需把表达式放在双括号内部,并且通过 $() 把整个双括号结构括起来,从而将运算结果展开成一个值。
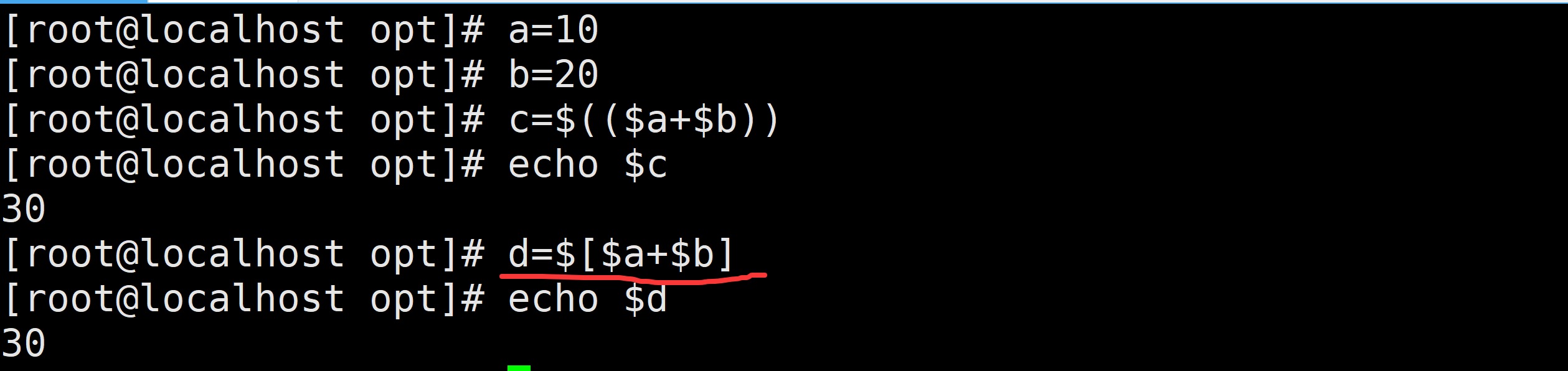
echo $[$a+$b]
此写法采用了中括号 [ ... ] 结构,这是较早期的 Shell 语法,同样用于算术扩展。它的功能和双括号结构类似,不过在表达式的书写上有一些限制,例如某些运算符需要添加转义符号,而且部分高级特性它并不支持。要注意的是,中括号必须用 $ 符号包裹,这样才能实现算术扩展。
在现代的 bash 脚本编写中,推荐优先使用双括号 ((...)) 结构,原因如下:
它的语法更加清晰直观。
支持更多的算术操作符和特性。
与其他编程语言(如 C、Python)的算术表达式更为接近,便于记忆和使用。
而中括号 [ ... ] 结构虽然兼容性良好,但由于其语法存在一些限制,在新脚本中使用得越来越少。
bash
#!/bin/bash
a=1
b=2
echo $(($a+$b)) # 输出 3
echo $[$a+$b] # 输出 3
# 双括号支持更复杂的表达式
echo $(($a+$b*2)) # 输出 5
echo $[$a+$b*2] # 输出 5
# 双括号支持自增操作
echo $((a++)) # 输出 1
echo $a # 输出 2
# 中括号的一些限制(例如取模运算需要转义)
echo $[$a % $b] # 输出 0使用let命令
基本语法 —
let 表达式
表达式:可以包含变量、算术运算符(如 +、-、*、/、%)、赋值运算符(如 =、+=、*=)等。
变量引用:let 命令中的变量名前不需要加 $ 符号(但加了也不会报错)。
案例 —
- 简单赋值运算
let a=1+2 # a = 3
let "a = 1 + 2" # 引号可处理包含空格的表达式
echo $a # 输出 3- 使用变量进行计算
a=5
let b=a*2 # b = 5 * 2 = 10
echo $b # 输出 10- 复合赋值运算符
a=10
let a+=5 # 等价于 a = a + 5,结果 a = 15
let a*=2 # 等价于 a = a * 2,结果 a = 30
echo $a # 输出 30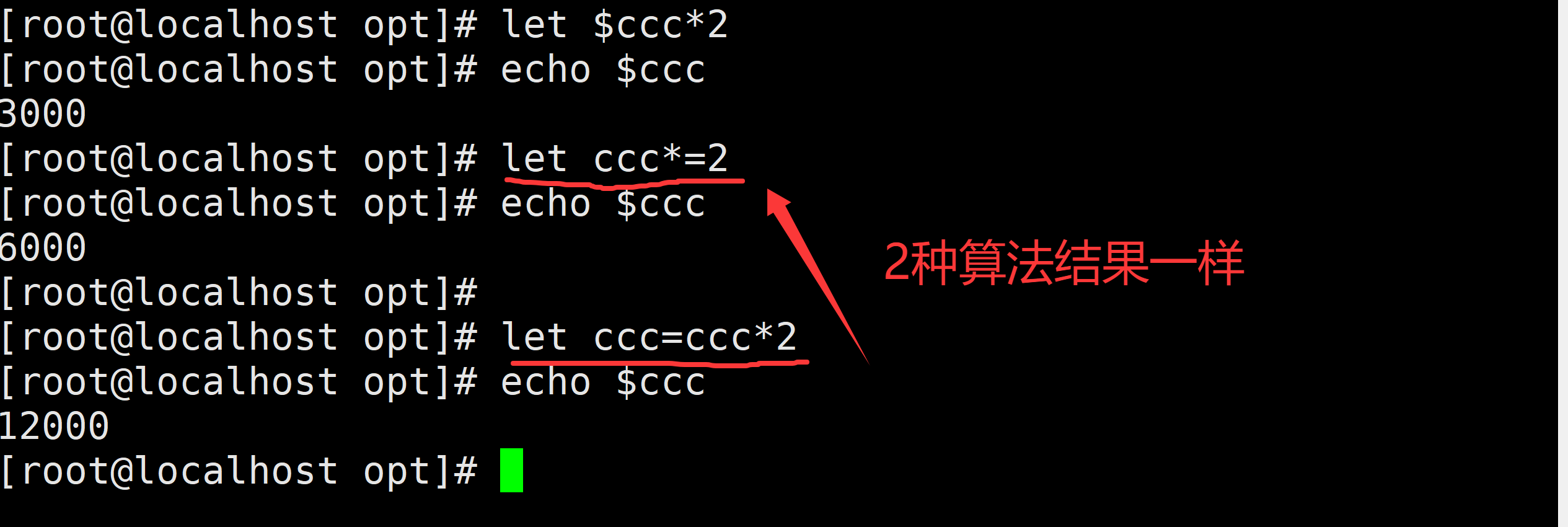
- 自增 / 自减运算
a=1
let a++ # 自增,等价于 a = a + 1
echo $a # 输出 2
let a-- # 自减,等价于 a = a - 1
echo $a # 输出 1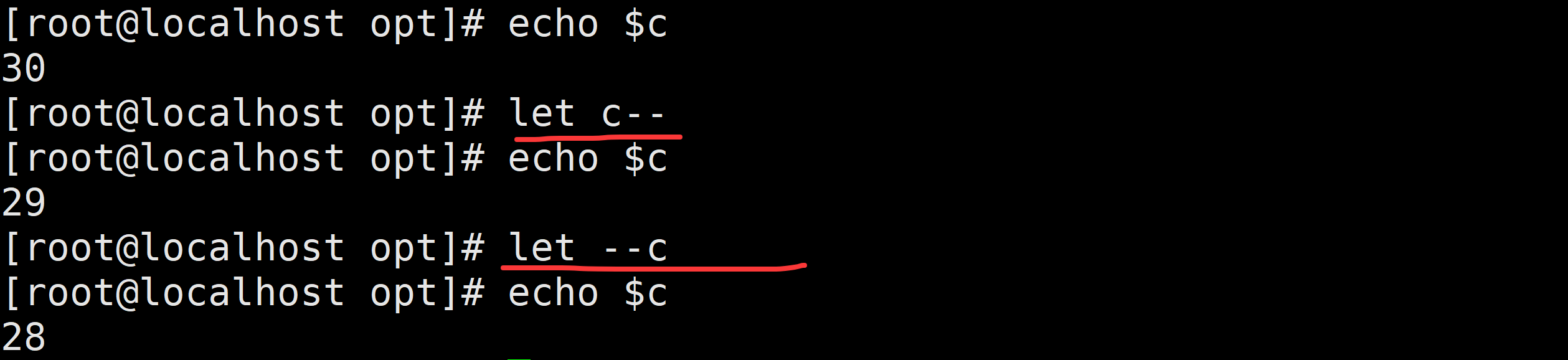
- 多个表达式用空格分隔
let "a=10 b=a*2 c=a+b" # 连续赋值,a=10, b=20, c=30
echo $c # 输出 30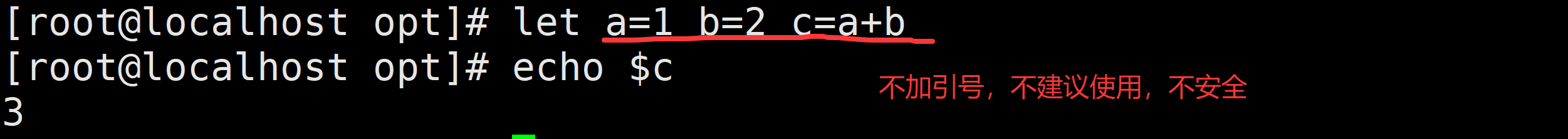
使用expr外部方程式
基本语法 —
expr expression
注意:
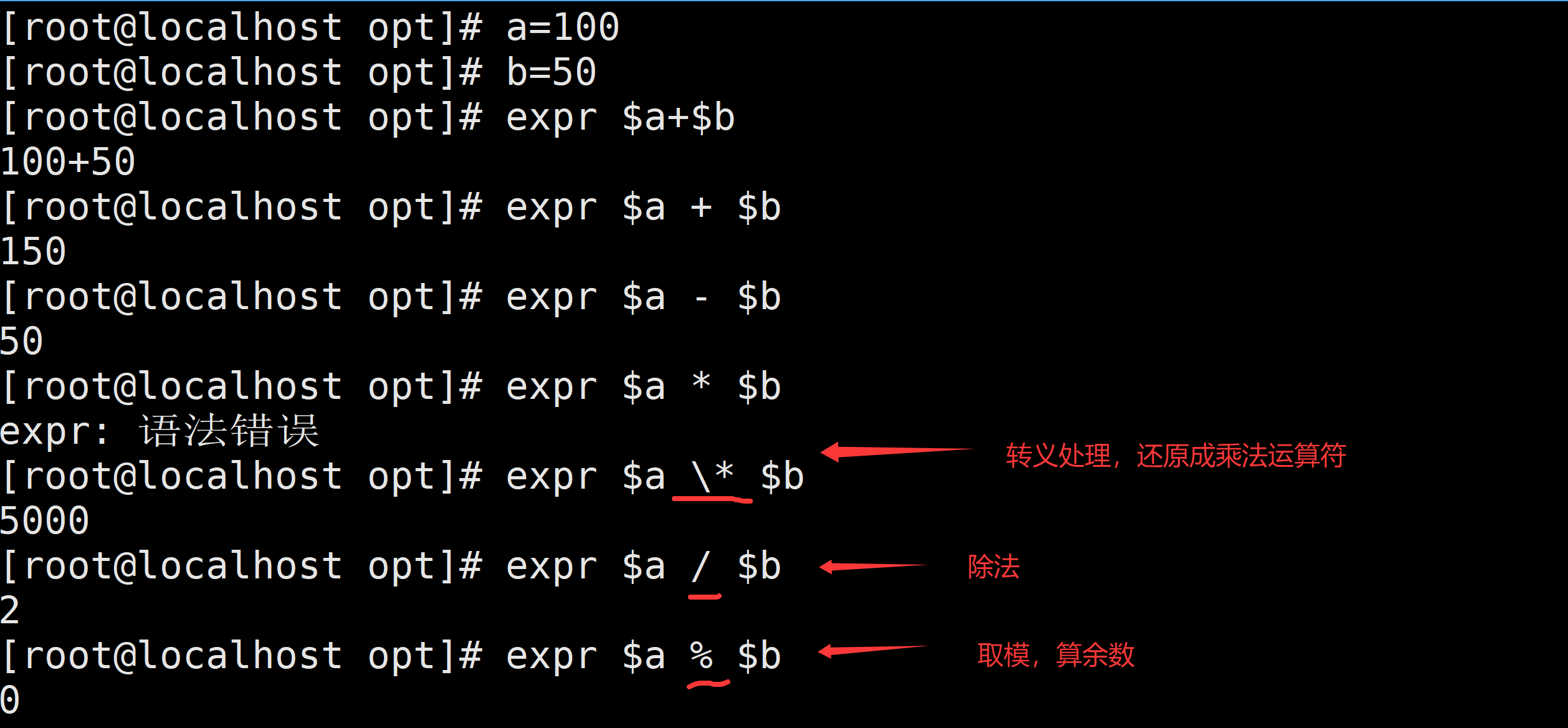
表达式中的运算符和操作数必须用空格分隔(如 2 + 3,而非 2+3)。
特殊字符(如 *、(、))需要转义(前面加 \)。
案例 —
- 加法与减法
expr 5 + 3 # 输出 8
expr 10 - 4 # 输出 6- 乘法与除法
expr 5 \* 3 # 输出 15(* 需要转义)
expr 10 / 3 # 输出 3(整数除法,直接截断小数)- 取模与幂运算
expr 10 % 3 # 输出 1(余数)
# expr 不直接支持幂运算,需结合其他工具(如 bc)
bc 是 Linux 系统中的一个命令行计算器,用于执行各种数学运算。它支持任意精度的算术运算,包括整数、小数和科学计数法。bc 是一个交互式的计算器,也可以通过脚本进行批量计算。 可以处理整数和浮点数计算。它还支持条件语句、循环以及函数定义,因此可以用来编写复杂的数学脚本。- 变量计算
a=5
b=3
expr $a + $b # 输出 83.字符串操作
字符串操作
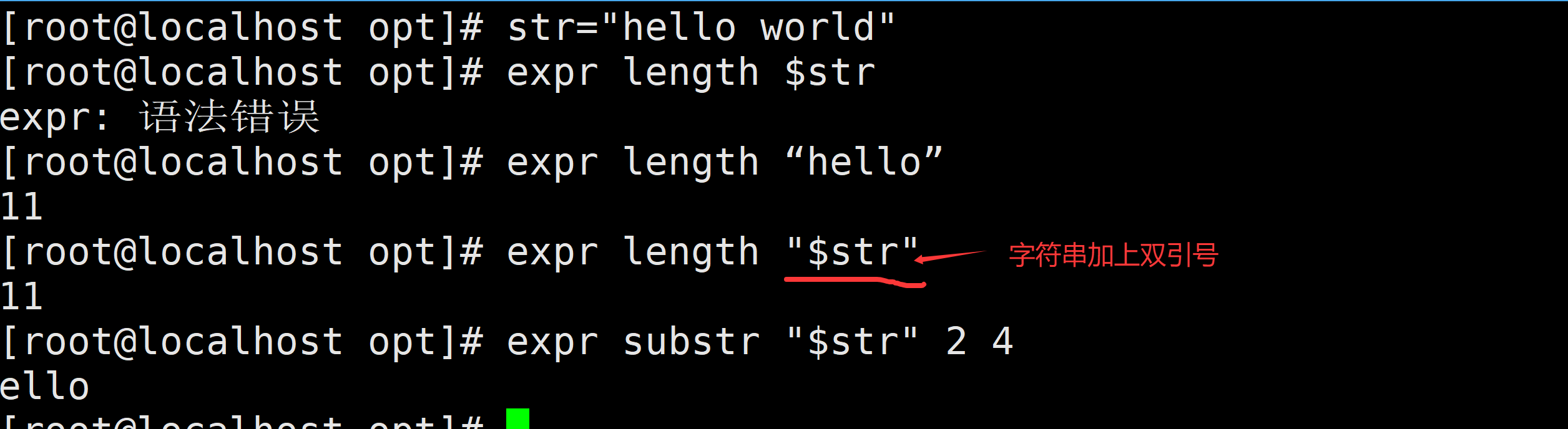
1.字符串长度
expr length "hello" # 输出 52.子串截取
str="hello world"
expr substr "$str" 2 4 # 输出 "ello"(从位置2开始,长度4)3.子串位置
expr index "hello" "l" # 输出 3(第一个 "l" 的位置,从1开始)题目 1:计算 5 + 3,分别用四种方式实现,并打印结果。
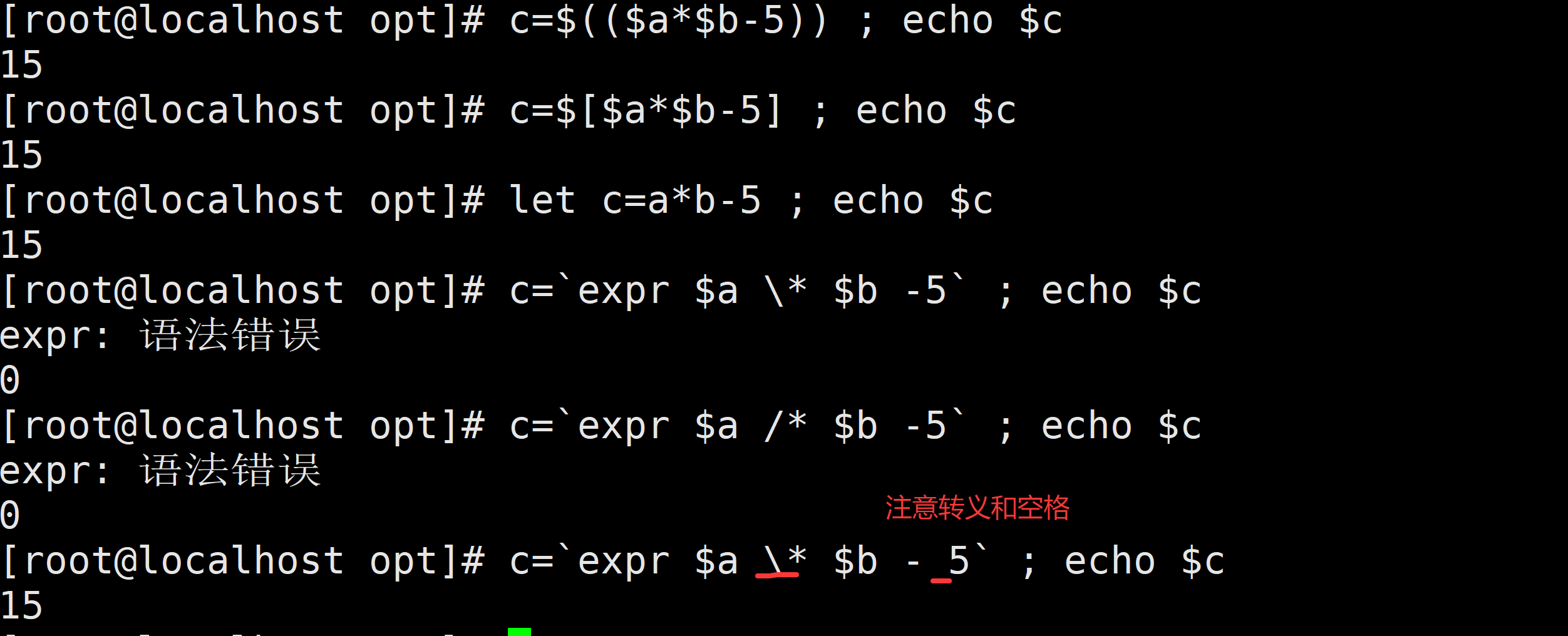
题目 2:定义变量 a=10,b=2,计算 a * b - 5,用四种方式实现。题目 1:计算 5 + 3,分别用四种方式实现,并打印结果。
[root@localhost opt]# a=$((5+3));echo $a
8
[root@localhost opt]# a=$[5+3];echo $a
8
[root@localhost opt]# let a=5+3;echo $a
8
[root@localhost opt]# a=$(expr 5 + 3) ; echo $a
8题目 2:定义变量 a=10,b=2,计算 a * b - 5,用四种方式实现。
[root@localhost opt]# a=10 b=2
[root@localhost opt]# c=$(($a*$b-5)); echo $c
15
[root@localhost opt]# c=$[$a*$b-5]; echo $c
15
[root@localhost opt]# let c=a*b-5; echo $c
15
[root@localhost opt]# c=`expr $a \* $b - 5`; echo $c
15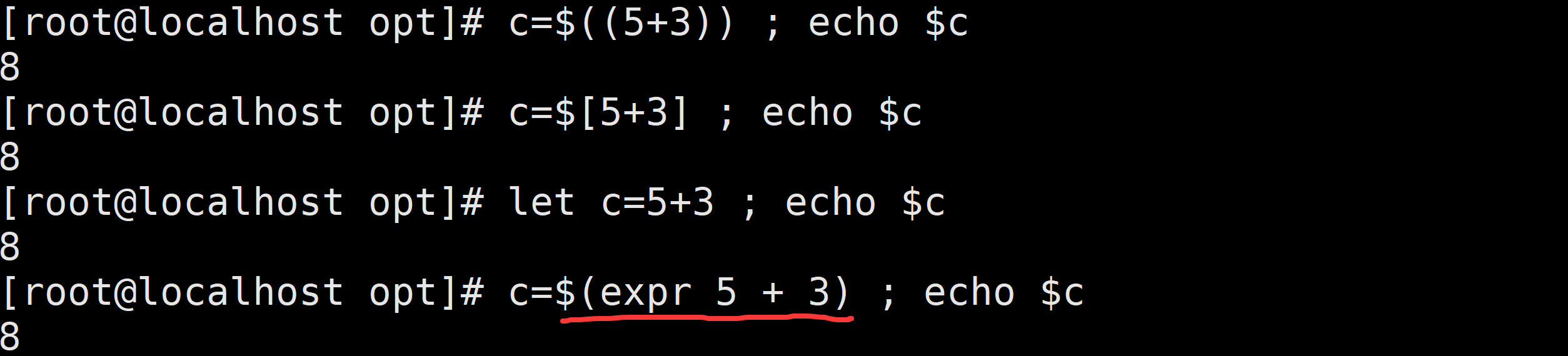
4.环境变量文件
$HOME/.bashrc # 当前用户的bash信息(aliase、umask等)$HOME/.bash_profile # 当前用户的环境变量()
/etc/bashrc # 使用bash,shell用户全局变量,别名,全局变量
/etc/profile # 系统和每个用户的环境变量信息,安装应用之后需要配置的地方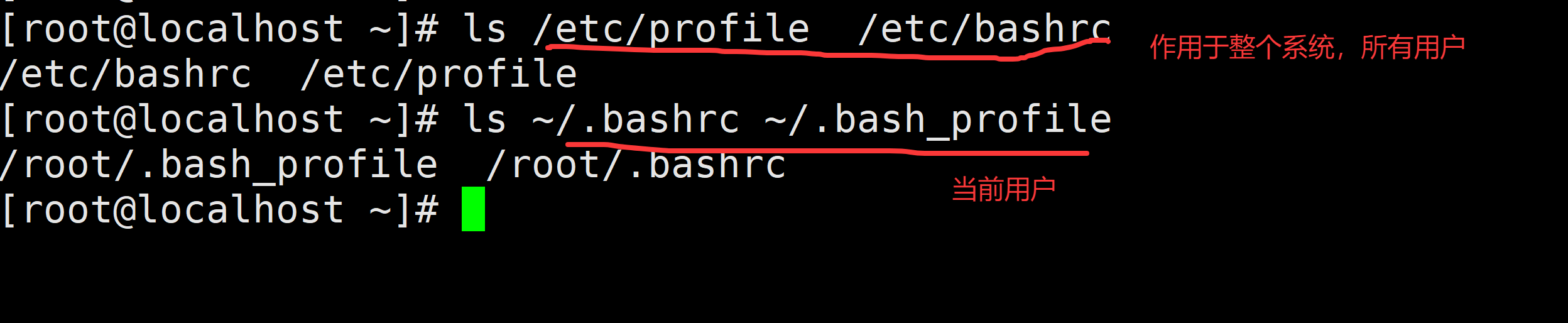


$HOME/.bashrc
Bash shell 的配置脚本,属于用户级配置文件(仅对当前用户生效)。
$HOME/.bash_profile
用户登录时执行的初始化脚本,用于设置环境变量、启动服务等登录相关配置。
/etc/bashrc
定义所有用户的交互式 Bash Shell的默认行为,属于系统级配置。
/etc/profile
定义所有用户登录时执行的环境变量、全局变量和脚本,属于系统级配置。
用户级配置(如~/.bash_profile)中的变量会覆盖/etc/profile中的同名变量。| 特性 | .bash_profile |
.bashrc |
|---|---|---|
| 执行场景 | 登录 Shell(如 SSH、本地终端登录) | 非登录 Shell(如bash启动的子 Shell) |
| 执行次数 | 登录时执行一次 | 每次启动子 Shell 时执行 |
| 典型用途 | 环境变量、系统服务启动 | 别名、函数定义、终端显示优化 |
| 加载顺序 | 先于.bashrc执行 |
通常由.bash_profile调用执行 |
在 Linux 系统中,这四个配置文件的执行顺序取决于 Shell 的启动方式(登录 Shell 或非登录 Shell)以及 变量的定义位置。以下是详细的执行顺序和覆盖规则:
一、执行顺序核心规则
- 登录 Shell(如 SSH 登录、su – user)
/etc/profile → ~/.bash_profile → ~/.bash_login → ~/.profile → ~/.bashrc → /etc/bashrc- 关键点:
- 系统级配置优先:先加载
/etc/profile。 - 用户级配置覆盖:
~/.bash_profile中的变量会覆盖/etc/profile中的同名变量。 .bashrc被间接加载:通常在.bash_profile中会通过source ~/.bashrc引用用户的.bashrc,而.bashrc又会引用/etc/bashrc。
- 系统级配置优先:先加载
- 非登录 Shell(如直接运行 bash 或执行脚本)
~/.bashrc → /etc/bashrc-
关键点:
-
仅加载用户和系统的 bashrc:不执行
/etc/profile和~/.bash_profile。 -
变量覆盖:
~/.bashrc中的变量会覆盖/etc/bashrc中的同名变量。
-
5.条件判断
5.1 概述
条件判断:就是对数据或者字符的判断,判断的结果只有两种,要么为真,要么为假。比如:1=1结果为真;1>2结果为假等
条件判断的结果:
- true:表示结果为真
- false:表示结果为假
shell中我们通常是对变量的判断,或者命令是否执行成功的判断
思考:如何判断一个命令是否执行成功?
$?:上一条命令执行后返回的状态,当返回状态值为0时表示执行正常,非0值表示执行异常或出错
5.2 语法
条件判断在shell中有三种表现形式,用哪一种都可以,但是在某一些情况下会存在一些差异(这些差异我们暂时不管,后面在单独说)
-
格式1: test 条件表达式
-
格式2: [ 条件表达式 ] # 注意:[]括号跟里面的内容之间都必须要存在一个空格
-
格式3: [[ 条件表达式 ]] # 注意:里层的[]括号跟里面的内容之间都必须要存在一个空格
test格式
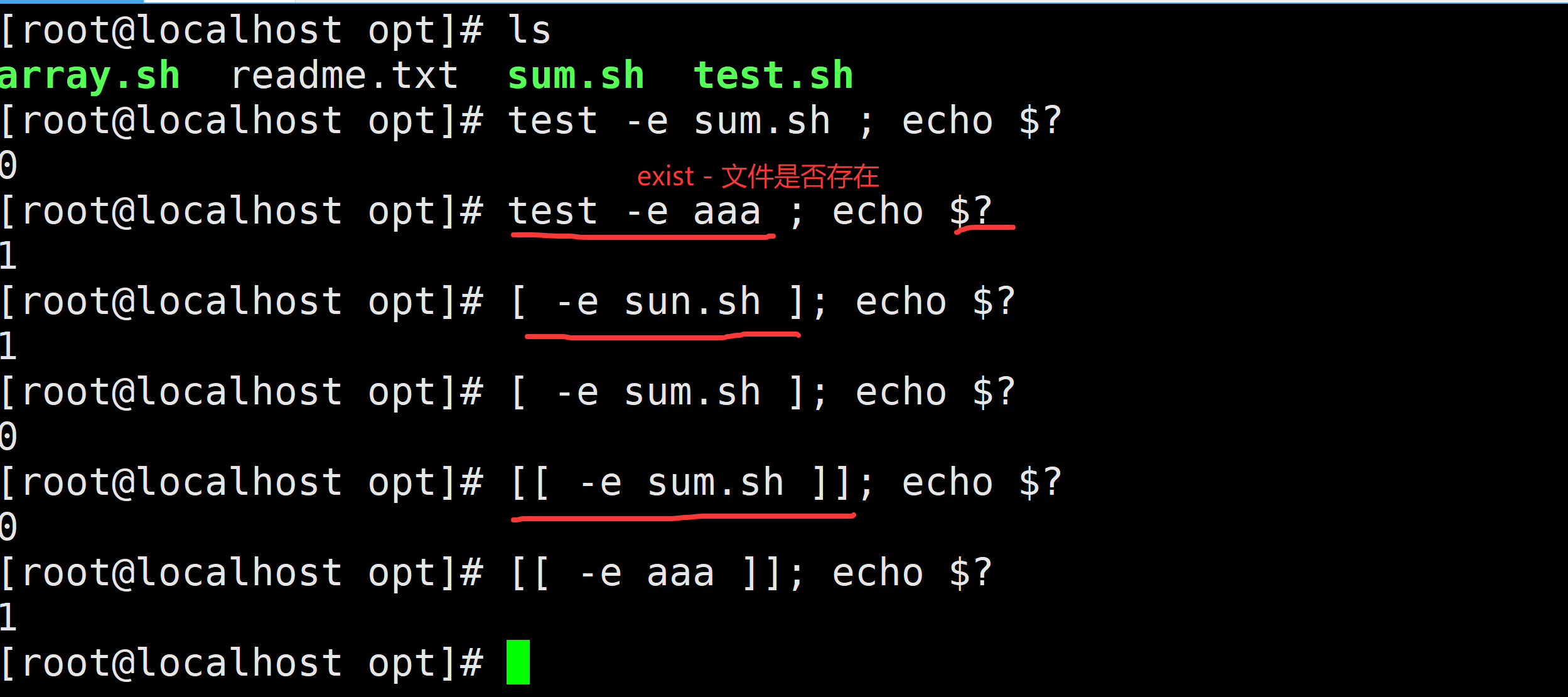
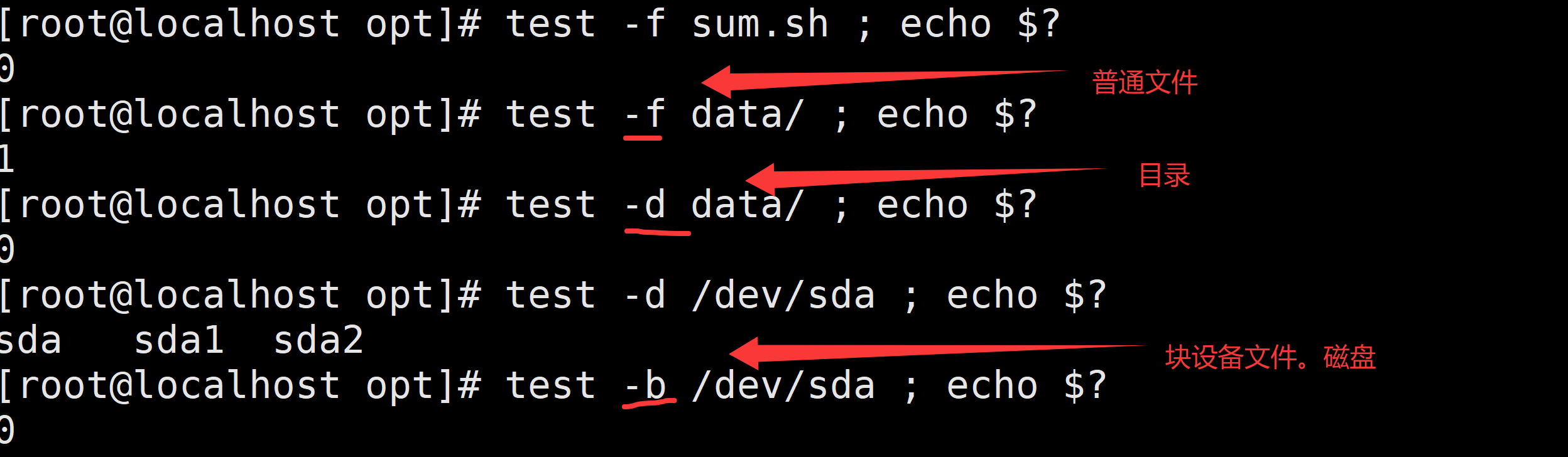
示例:
三种语法格式:
test -e abc.txt # 只要文件存在条件为真
[ -d aaa ] # 判断目录是否存在,存在条件为真
[ ! -d aaa ] # 判断目录是否存在,不存在条件为真
[[ -f abc.txt ]] # 判断文件是否存在,并且是一个普通的文件5.3 常见判断参数
1)与文件存在与否的判断
-e(Exist) 是否存在(不管是文件还是目录,只要存在,条件就成立)
-f(file) 是否为普通文件
-d(directory) 是否为目录
-S socket
-p pipe
-c character
-b block 块设备文件、磁盘
-L 软link
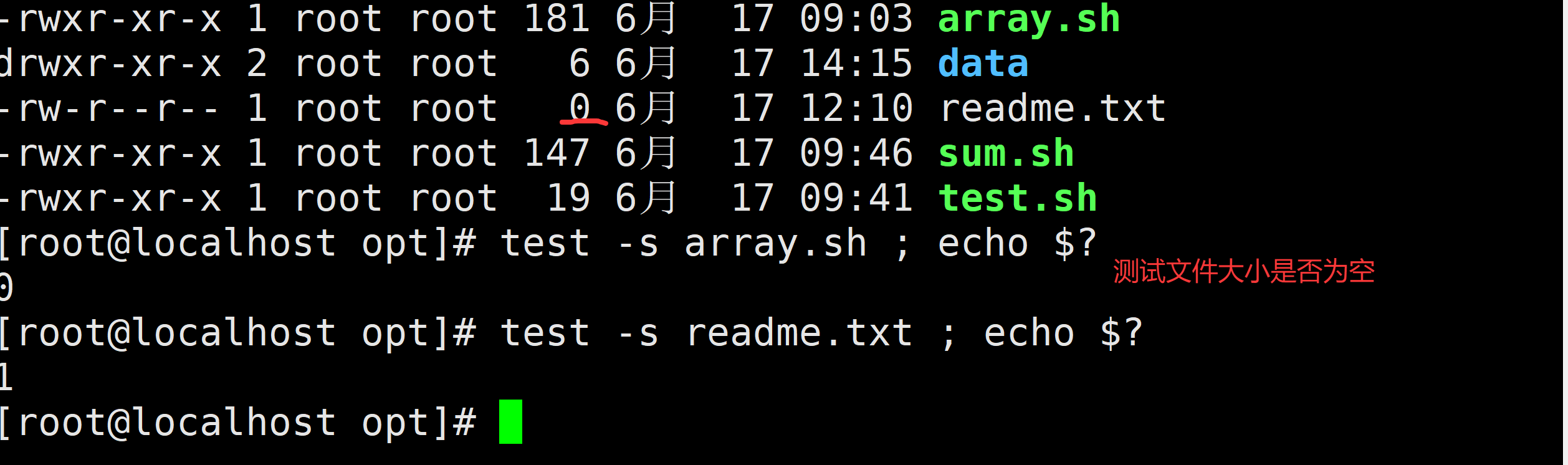
-s(size) 判断文件是否有内容(大小),非空文件条件满足
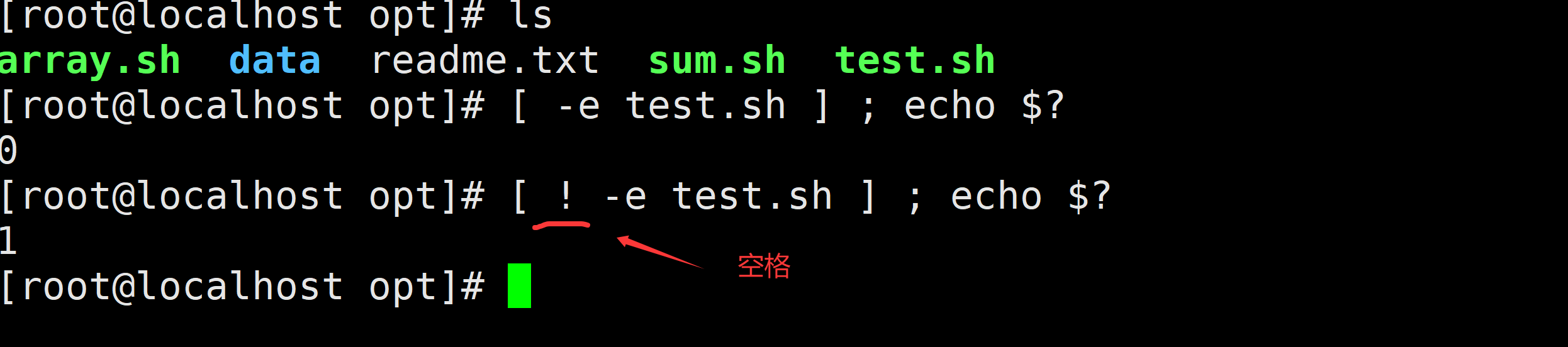
! 表示取反(真变假 假变真); (分号):表示执行完上一个命令,接着执行下一个命令
查看文件类型
查找指定类型的文件

-s选项 文件是否为空
取反
2)文件权限相关的判断
文件权限相关的判断
-r 当前用户对其是否可读
-w 当前用户对其是否可写
-x 当前用户对其是否可执行
-u 是否有suid
-g 是否sgid
-k 是否有t位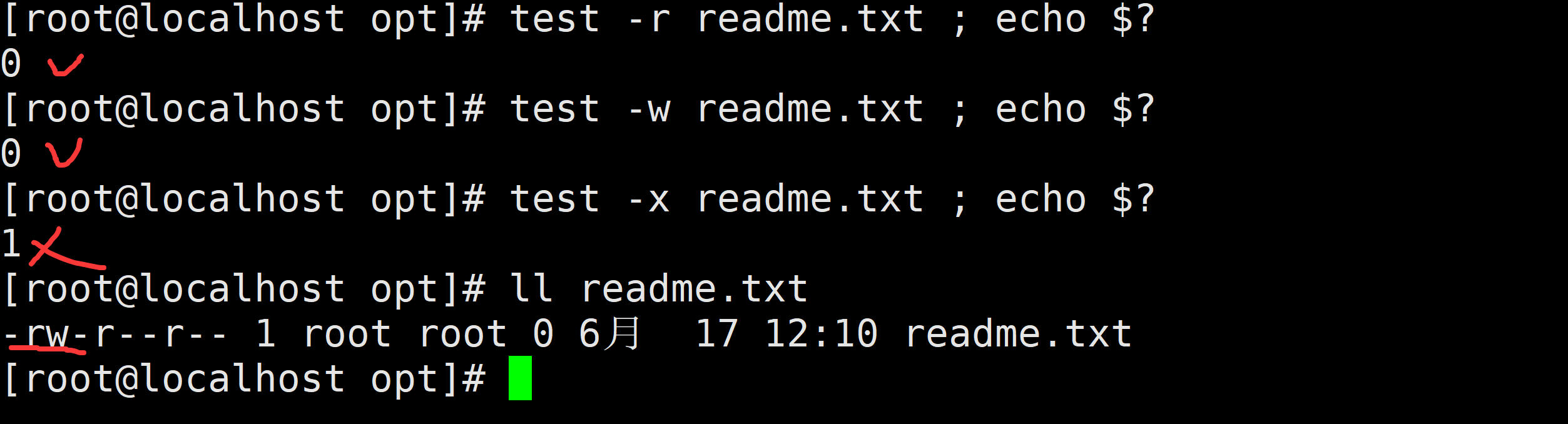
特殊权限 – passwd命令

判断执行passwd命令的文件是否有特殊权限s

which命令的作用

特殊的t权限

3)两个文件的比较判断
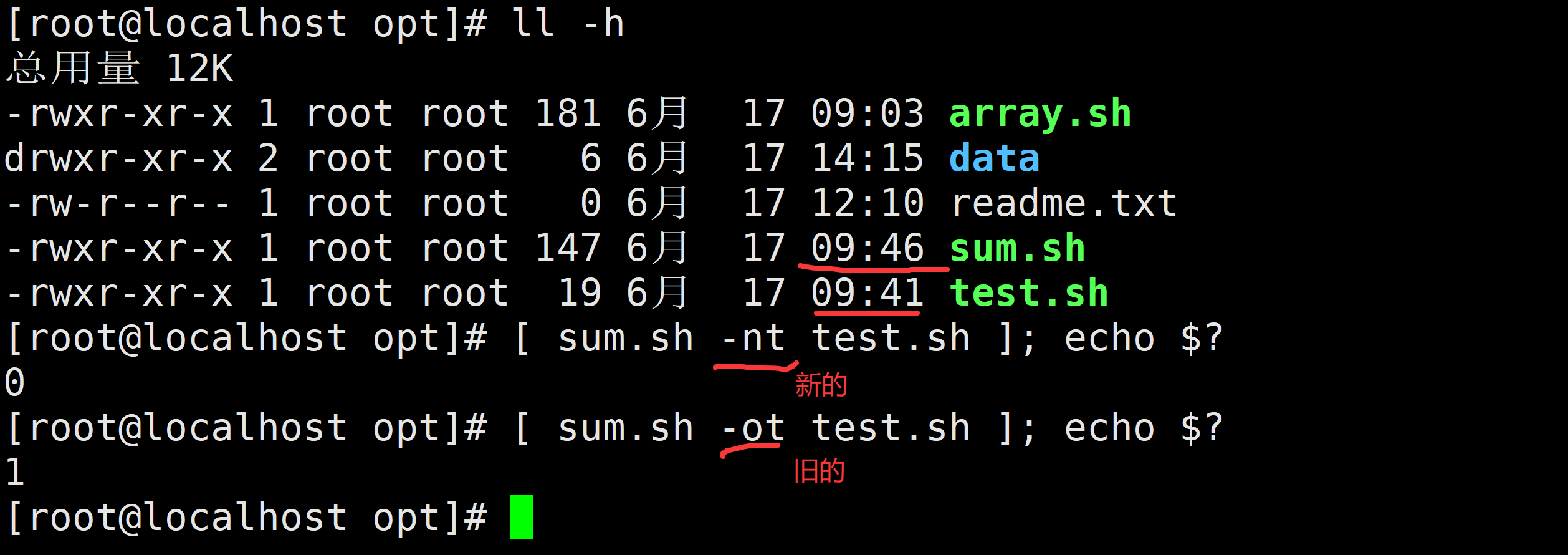
两个文件的比较判断(-nt -ot -ef)
file1 -nt file2 比较file1是否比file2新(新旧主要判断修改的时间) new
file1 -ot file2 比较file1是否比file2旧 old
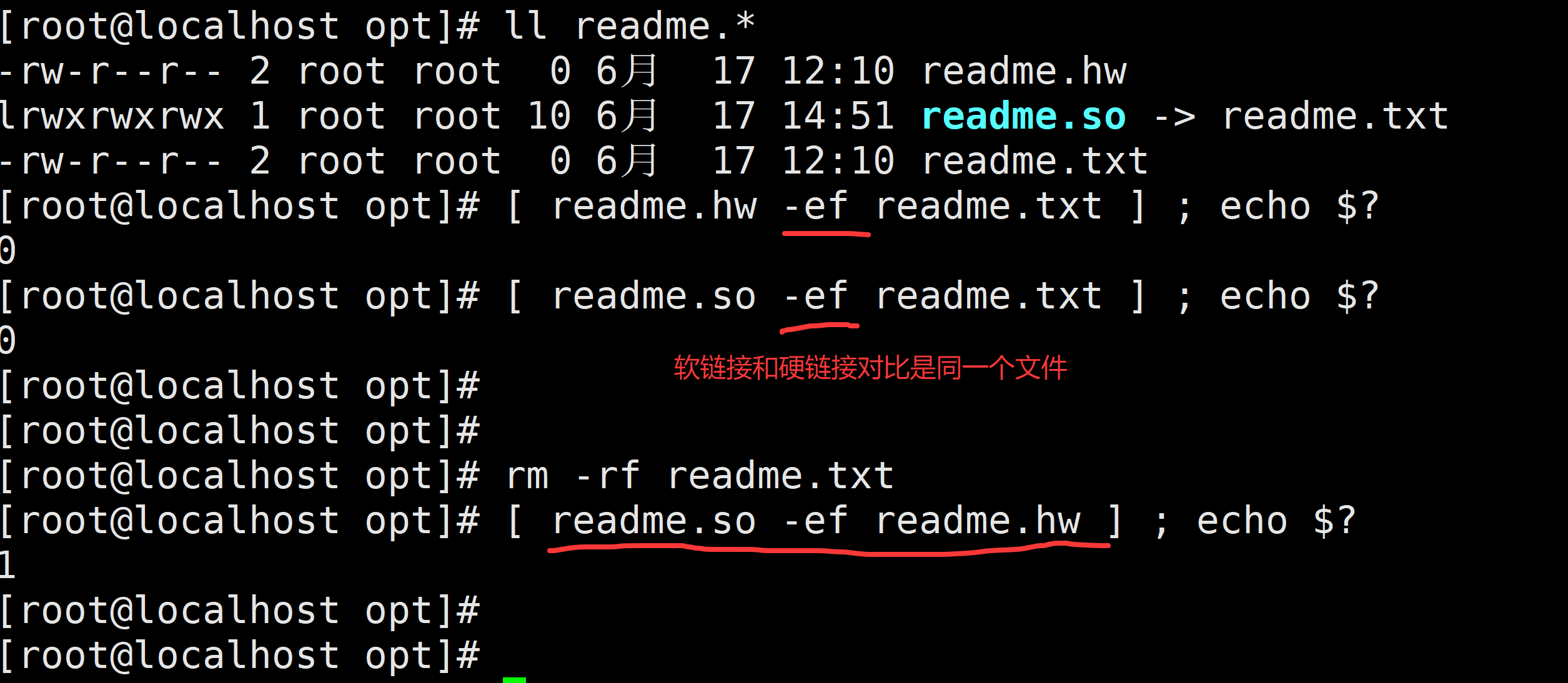
file1 -ef file2 比较是否为同一个文件 equals
-nt : new than 。。。
-ot : old than ..... Linux Shell 中,file1 -nt file2 是一个用于比较文件修改时间的测试表达式,通常在 if 语句或条件判断中使用。其中:
-nt 是比较操作符,含义为 newer than(比... 更新)。
file1 和 file2 是要比较的两个文件路径。查看文件的最后修改时间
新旧判断
软硬链接
需求:判断abc.txt是否比test.sh文件新
[ abc.txt -nt test.sh ];echo $?需求:判断abc.txt是否比test.sh文件旧
[ abc.txt -ot test.sh ];echo $?需求:给abc.txt文件创建一个硬链接a1,判断abc.txt与a1是否为同一个文件
ln abc.txt a1
[ abc.txt -ef a1 ];echo $?需求:给abc.txt文件创建一个软链接a2,判断abc.txt与a2是否为同一个文件
ln -s abc.txt a2
[ abc.txt -ef a2 ];echo $?
需求:判断`abc.txt`是否比`test.sh`文件新
需求:判断`abc.txt`是否比`test.sh`文件旧
需求:给`abc.txt`文件创建一个硬链接`a1`,判断`abc.txt`与`a1`是否为同一个文件
需求:给`abc.txt`文件创建一个软链接`a2`,判断`abc.txt`与`a2`是否为同一个文件4)整数判断(大于等于小于)
整数判断(需要记忆)
-eq 相等 equals =
-ne 不等 not equals !=
-gt 大于 greater than >
-lt 小于 less than <
-ge 大于等于 greater equals >=
-le 小于等于 less equals <= 早期的 Shell(如 Bourne Shell)为避免与重定向符号(
>、<)冲突,设计了-gt、-lt等符号:为了保持语法一致性:在
[ ... ]测试命令中,所有操作符统一使用-xxx格式避免歧义:Shell 需要明确区分数值比较和字符串比较
需求:判断5与4是否相等
[ 5 -eq 4 ];echo $?需求:判断5是否大于4
[ 5 -gt 4 ];echo $?需求:判断5是否小于4
[ 5 -lt 4 ];echo $?需求:判断1是否不等于0
[ ! 1 -eq 0 ];echo $?
需求:判断5与4是否相等
需求:判断5是否大于4
需求:判断5是否小于4
需求:判断1是否不等于05)字符串之间的判断
-z 是否为空字符串 字符串长度为0,就成立
-n 是否为非空字符串 只要字符串非空,就是成立(如果字符串为空,则必须使用""包起来)
string1 = string2 是否相等
string1 != string2 不等
判断字符串是否相等

前提:定义两个变量AAA=hello与BBB=world
需求:判断变量AAA是否为空字符串
[ -z AAA ];echo $?需求:判断BBB是否为非空字符串
[ -n AAA ];echo $?
[ ! -z AAA ];echo $?需求:判断AAA与BBB字符是否相等
[ AAA = BBB ];echo $?需求:判断AAA与BBB字符是否不相等
[ AAA != BBB ];echo $?
[ ! AAA = BBB ];echo $?
前提:定义两个变量`AAA=hello`与`BBB=world`
需求:判断变量AAA是否为空字符串
需求:判断BBB是否为非空字符串
需求:判断AAA与BBB字符是否相等
需求:判断AAA与BBB字符是否不相等课堂案例
需求1:定义一个变量name1=zhangsan,使用交互式方式给变量name2赋值,判断name1是否等于name2
需求2:判断root账号的家目录中是否存在aaa目录

需求3:使用交互方式给变量A1与A2赋值,判断A1是否大于A2`

需求4:使用交互式方式给变量name3赋值,判断name3是否有内容

需求5:判断root账号的家目录中是否存在readme.txt文件,如果不存在,则创建该文件
6.逻辑表达式(&& || )
6.1 概述
在上一章中,我们都是单个条件的判断,如果有多个条件的判断,我们就得分开几个步骤执行,而且上一个步骤的结果或影响下一个步骤
那么,如果存在多个条件,那么条件与条件之间的关系是如何呢?
生活举例:
在深圳买车要上牌的话,需要摇号,那么摇号就会存在一些条件
- 购买社保需要满2年
- 需要有驾驶证
请问,这两个条件是必须同时满足还是只要满足一个就可以了?
6.2 语法
| 符号 | 作用 | 说明 | ||
|---|---|---|---|---|
| -a && | 逻辑与(and) | 两个条件同时满足,整个大条件为真 | ||
| -o \ | \ | 逻辑或(or) | 两个条件满足任意一个,整个大条件为真 |
在逻辑与运算中,只要有一个表达式的值为false,那么结果就可以判定为false了,没有必要将所有表达式的值都计算出来。同理在逻辑或运算中,一旦发现值为true,右边的表达式将不再参与运算。
- 逻辑与:如果左边为真,右边执行;如果左边为假,右边不执行。
- 逻辑或:如果左边为假,右边执行;如果左边为真,右边不执行。
示例:
[ 1 -eq 1 -a 1 -ne 0 ] # 前面为真,后面也为真,整个运算结果为真
[ 1 -eq 1 ] && [ 1 -ne 0 ] # 相较上面的另外一种写法
[ 1 -eq 1 -o 1 -ne 1 ] # 前面为真,整个运算结果为真(如果前面为真,与后面的表达式就没有关系了)
[ 1 -eq 1 ] || [ 1 -ne 1 ] # 相较上面的另外一种写法与操作 – – – 2种表示方法:

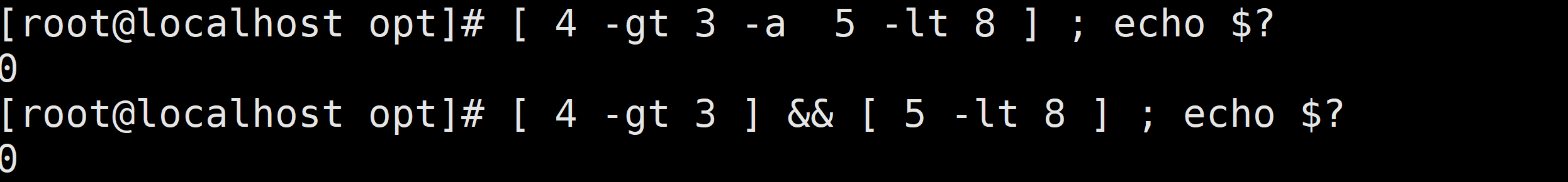
或操作2种表示方法:

6.3 小结
1、; && ||都可以用来分割命令或者表达式
2、; 完全不考虑前面的语句是否正确执行,都会执行;号后面的内容
3、&& 需要考虑&&前面的语句的正确性,前面语句正确执行才会执行&&后的内容;反之亦然(./configure && make && make install)
4、|| 需要考虑||前面的语句的非正确性,前面语句执行错误才会执行||后的内容;反之亦然
5、如果&&和||一起出现,从左往右依次看,按照以上原则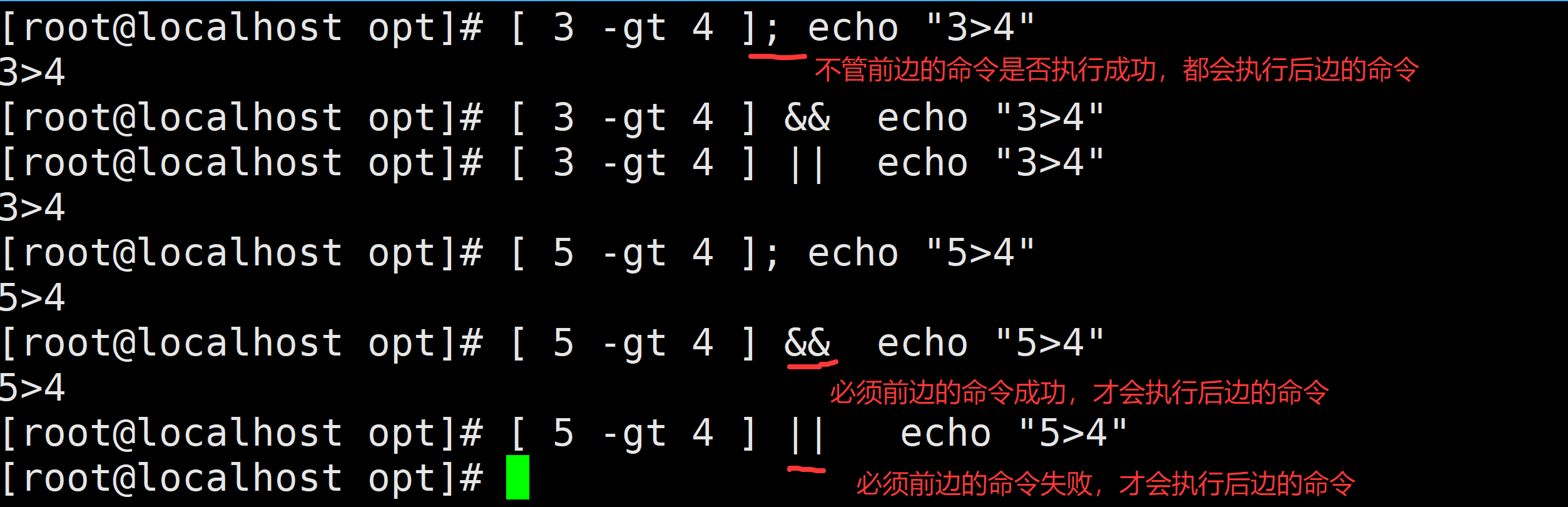
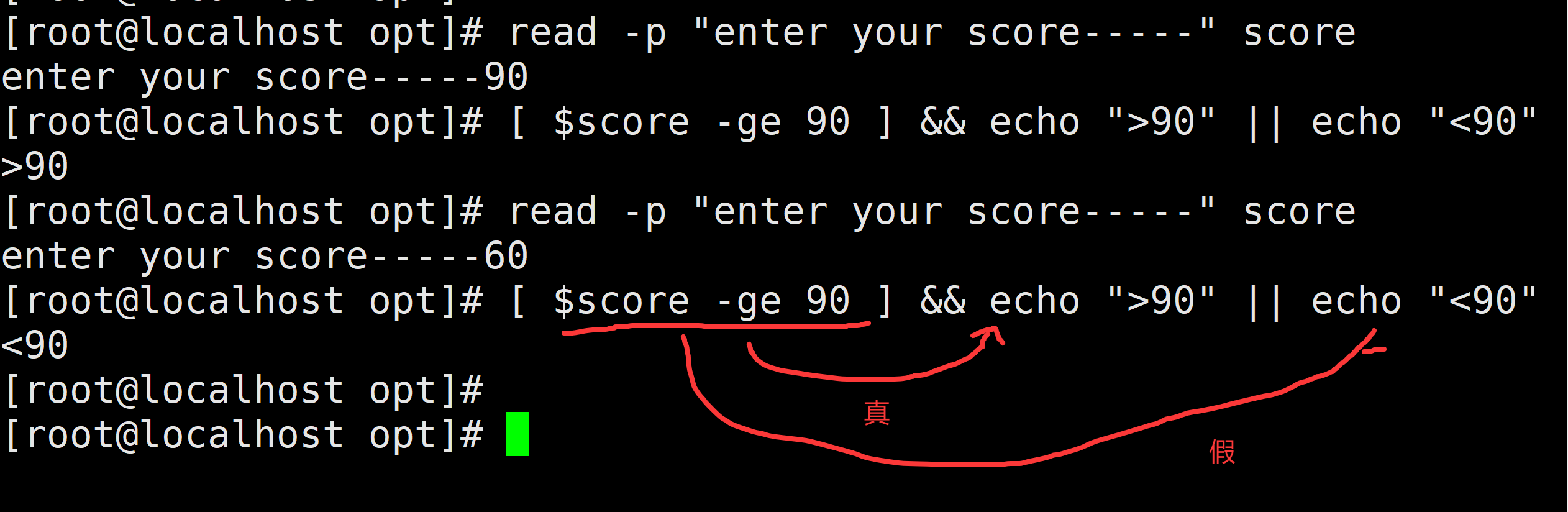
[]与[[]]的区别
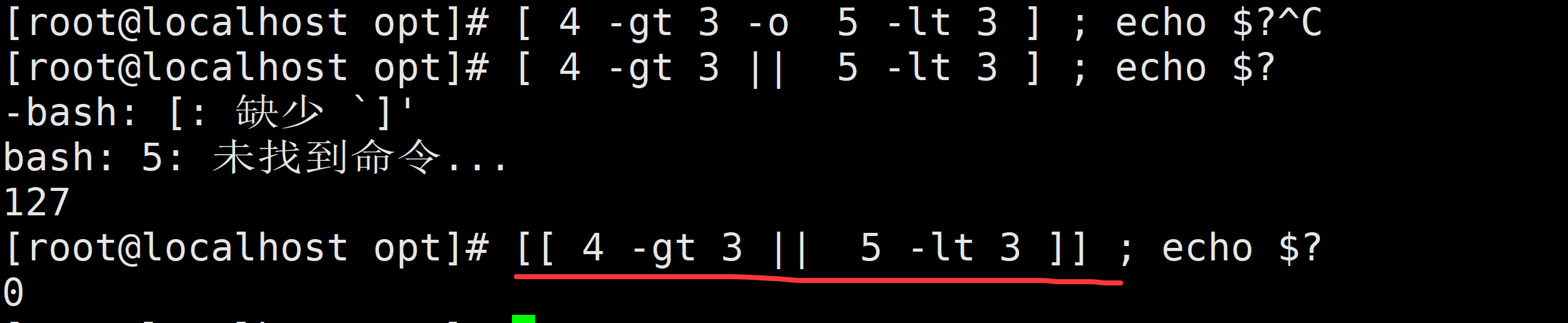
[ 1 -eq 0 -a 1 -ne 0 ];echo $?
[ 1 -eq 0 && 1 -ne 0 ];echo $?
[[ 1 -eq 0 && 1 -ne 0 ]];echo $?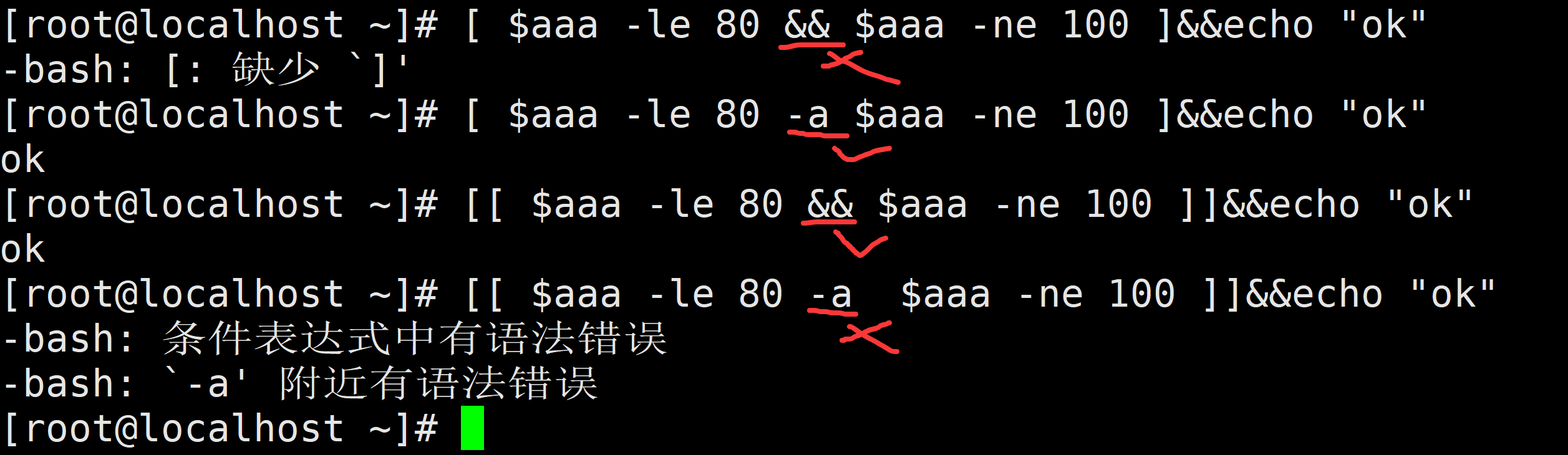
6.4 课堂练习
需求1:比较1和0的大小,如果为真,则显示1大于0
需求2:比较1和0的大小,如果为真,则显示1大于0,如果为假,则显示1小于0

需求3:定义一个变量score=81,判断score大于80,小于100,则显示优秀

需求4:定义一个变量uid=0,如果uid等于0,则显示为root用户,否则,则显示非root用户

需求5:判断当前用户是否为root用户

7.流程控制(if else)
7.1 概述
1)流程控制
在一个程序执行的过程中,各条语句的执行顺序对程序的结果是有直接影响的。所以,我们必须清楚每条语句的执行流程。而且,很多时候要通过控制语句的执行顺序来实现我们想要的功能
2)分支
分支,读音fēn zhī,汉语词语,意思为从总体或一个系统中分出的部分。通俗的说就是可以有不同的选项可供选择
3)举例
如:今天下雨我就不去上班了。 有两个选择(上班或者不上班 取决的条件为:是否下雨)
如:中了500万我就立马辞职。有两个选择(辞职或者不辞职 取决的条件为:是否中500万)
7.2 语法
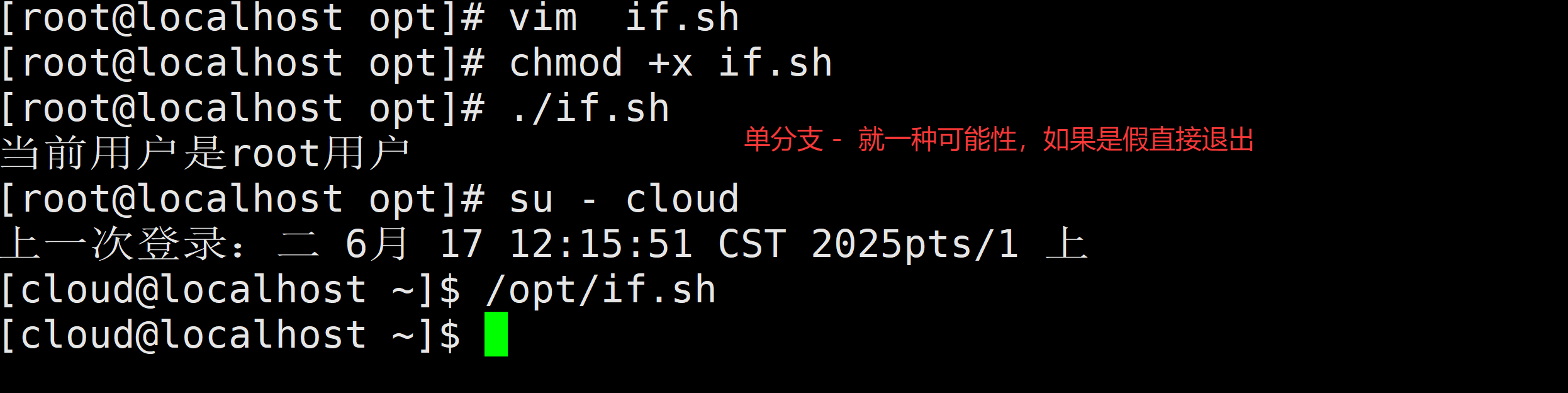
1)单分支
if [ condition ];then
command
command
fi以上相当于逻辑运算中的
[ 条件 ] && command

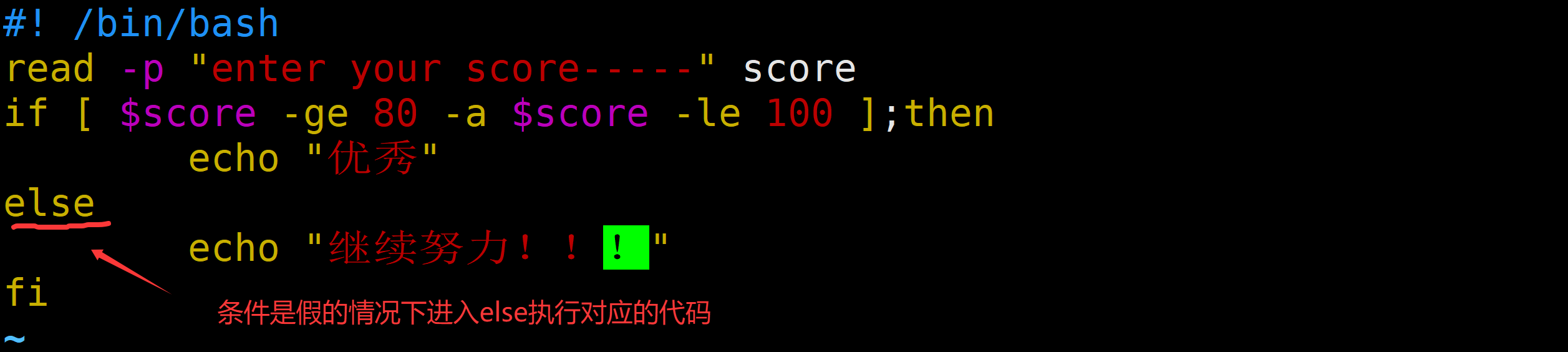
2)双分支
if [ condition ];then
command1
else
command2
fi以上相当于逻辑运算中的
[ 条件 ] && command1 || command2


3)多分支
if [ condition1 ];then
command1 结束
elif [ condition2 ];then
command2 结束
elif [ condition3 ];then
command3 结束
else
command4
fi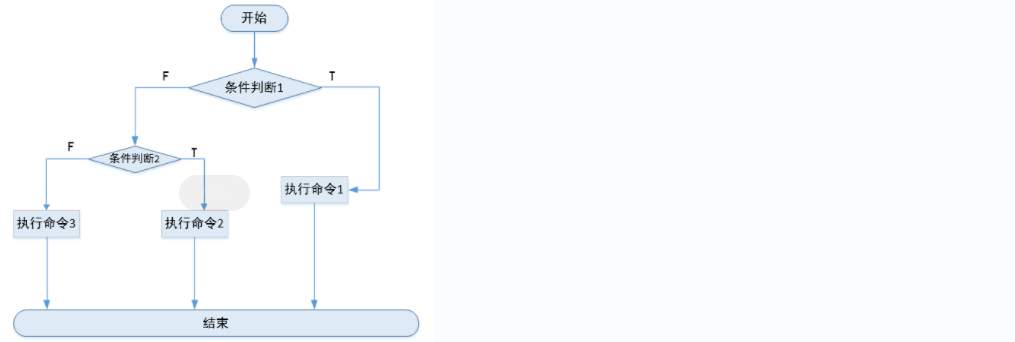
4)分支嵌套
if [ condition1 ];then
command1
if [ condition2 ];then
command2
fi
else
if [ condition3 ];then
command3
elif [ condition4 ];then
command4
else
command5
fi
fi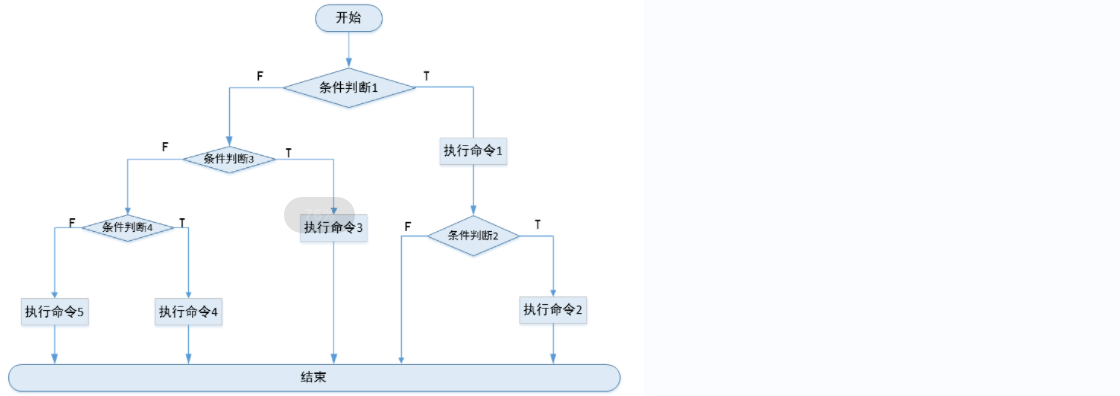
8.for语句
1.1 概述
循环:事物周而复始地运动和变化。就是重复做相同的事情。
注意:相同的事情(可以是一模一样的事情,也可以是性质相同的事情)
比如:
连续输出10次“我爱你” —— 一模一样的事情
连续输出0-9 10个整数 —— 性质相同的事情
代码示例:
#!/bin/bash
# 要求打印5遍我喜欢你
echo "我喜欢你"
echo "我喜欢你"
echo "我喜欢你"
echo "我喜欢你"
echo "我喜欢你"使用循环之后:
#!/bin/bash
# 要求打印5遍我喜欢你
for i in {1..5}
do
echo "我喜欢你"
done1.2 列表循环
1)语法结构
列表for循环:用于将一组命令执行已知的次数,下面给出了for循环语句的基本格式:
for variable in {list}
do
command
command
…
done
或者
for variable in a b c
do
command
command
donevariable:是一个变量,可以用任意名字来表示,通常情况下我们都使用字母
i1..10..2 : 2表示步长,就是指i每次变化的值

2)示例说明
需求1:输出1-10之间的数字

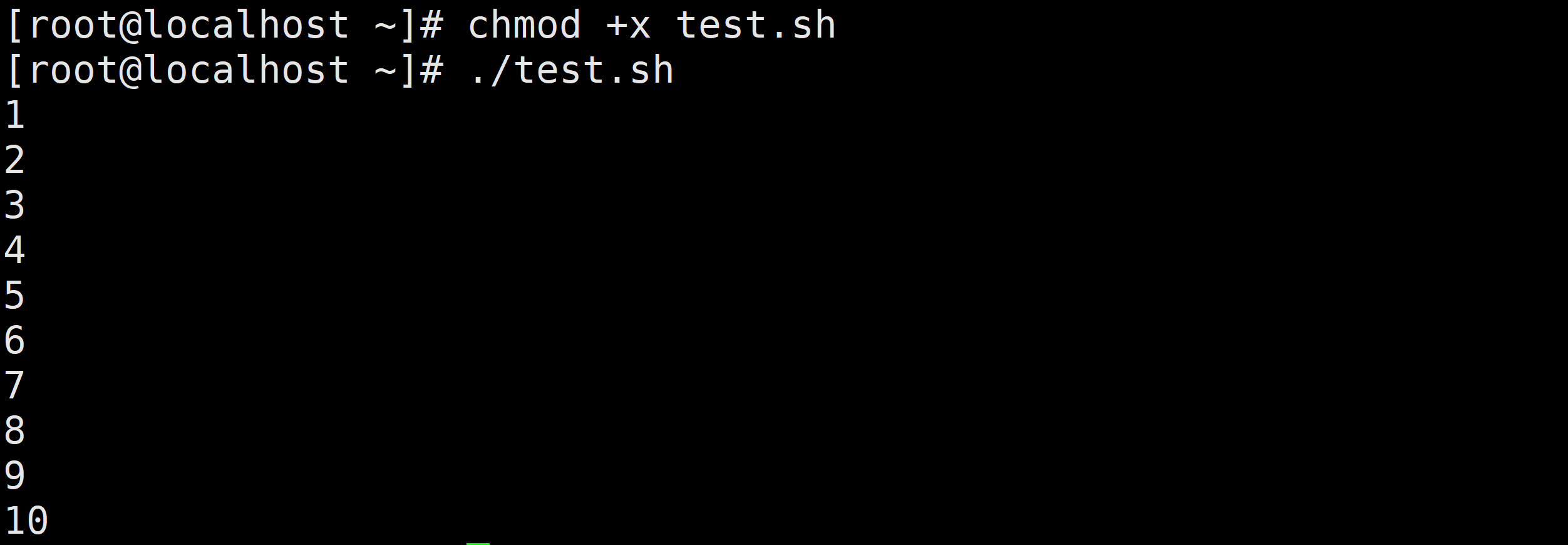
需求2:输出10-1之间的数字

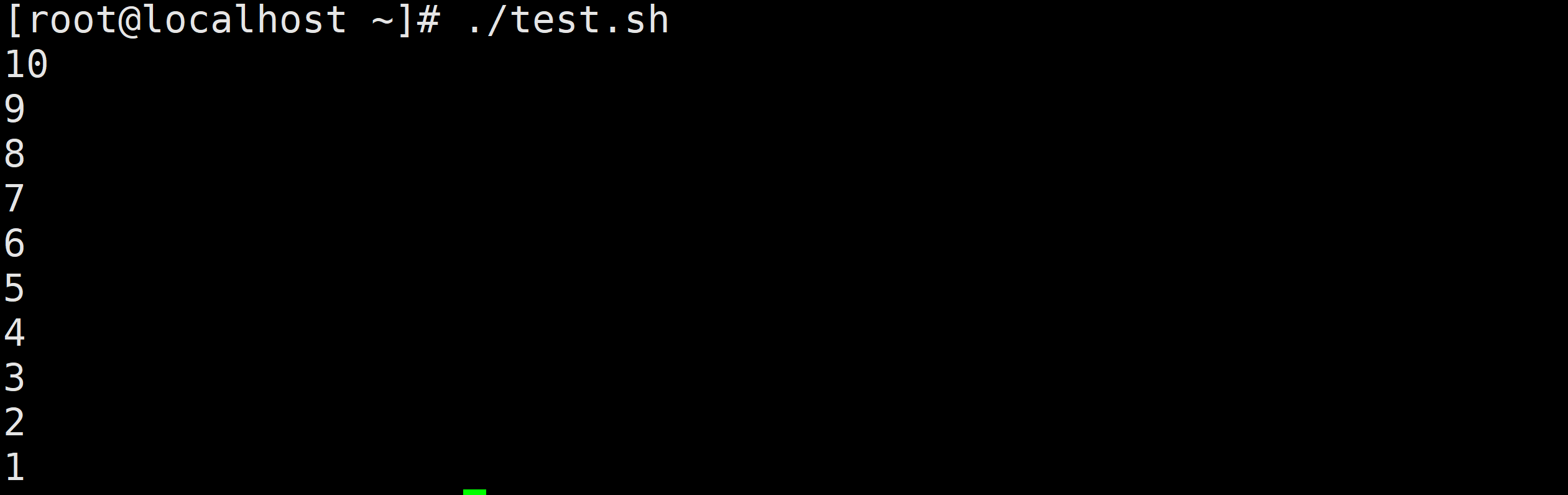
需求3:输出a,b,d,e几个字母

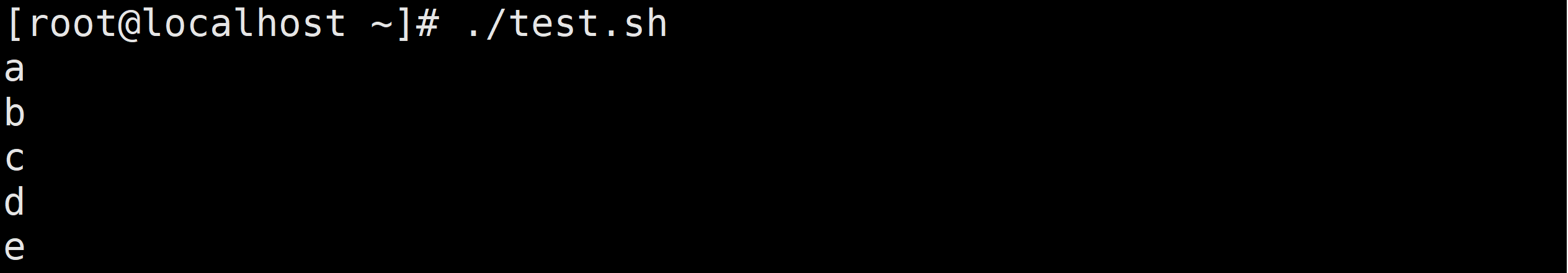
需求4:输出1-10之间的奇数



1.3 非列表循环
不带列表的for循环执行时由用户指定参数和参数的个数,下面给出了不带列表的for循环的基本格式:1.sh 1 2 3
for variable
do
command
command
…
done需求1:输出a,b,c,d几个字母

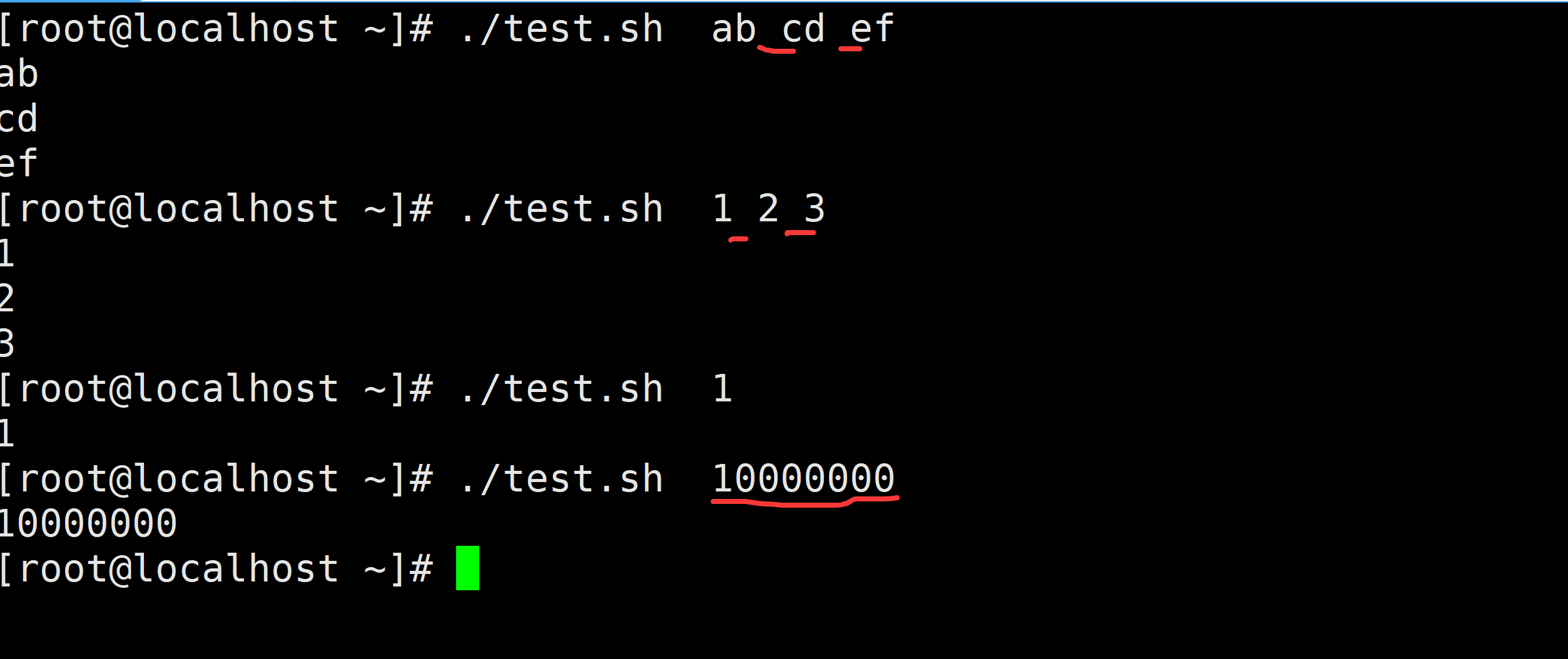
1.4 类C循环
类C风格的循环就是参照C语言的风格
for(( 初始化语句;条件判断语句;条件控制语句 ))
循环体语句
for(( expr1;expr2;expr3 ))
do
command
command
…
done
for(( i=1;i<=10;i++ ))
do
echo $i
done
执行流程:
①执行初始化语句
②执行条件判断语句,看其结果是true还是false
如果是false,循环结束
如果是true,继续执行
③执行循环体语句
④执行条件控制语句
⑤回到②继续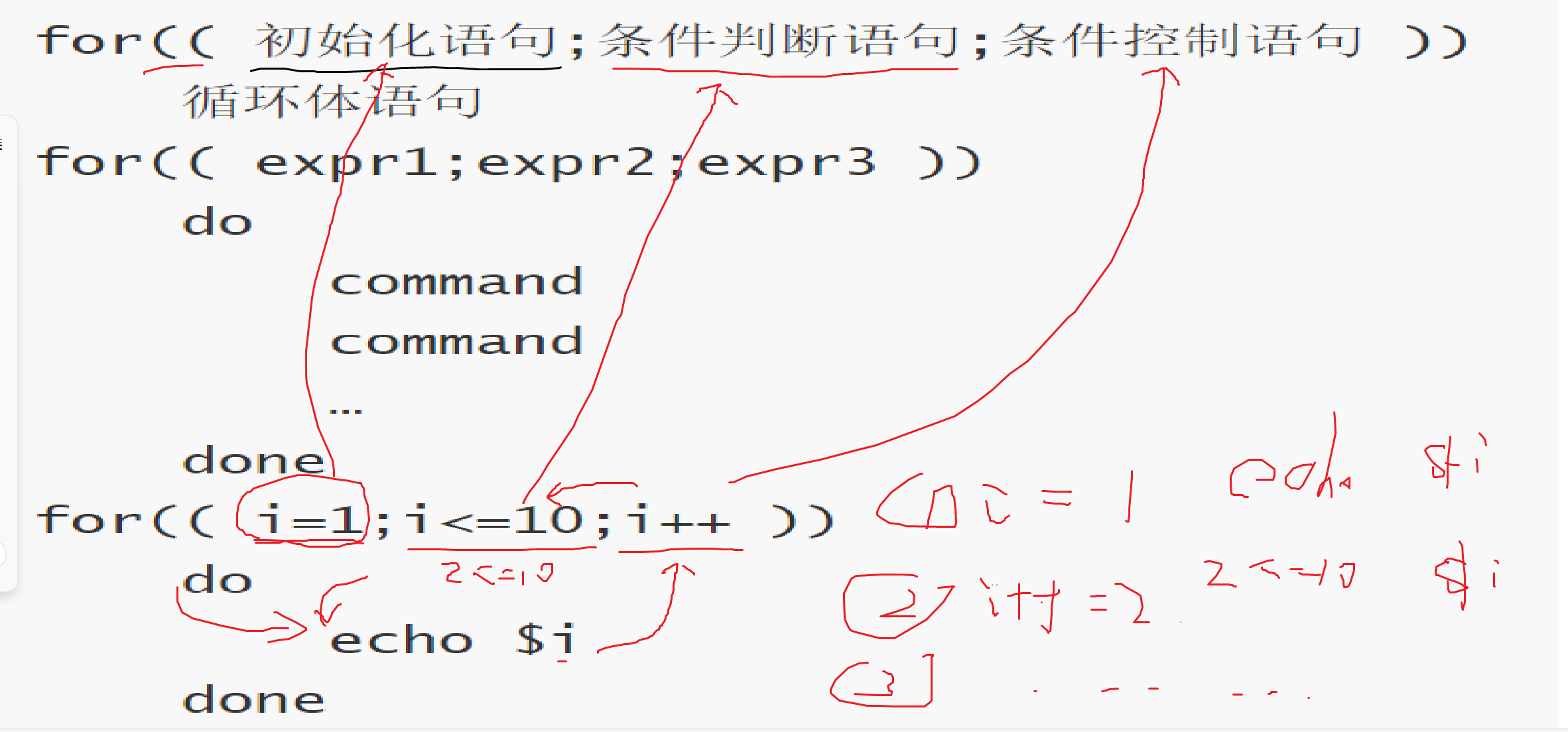
需求:输出1-10之间的数字

1.5 课堂案例
需求1:计算1到10的奇数之和(重点)


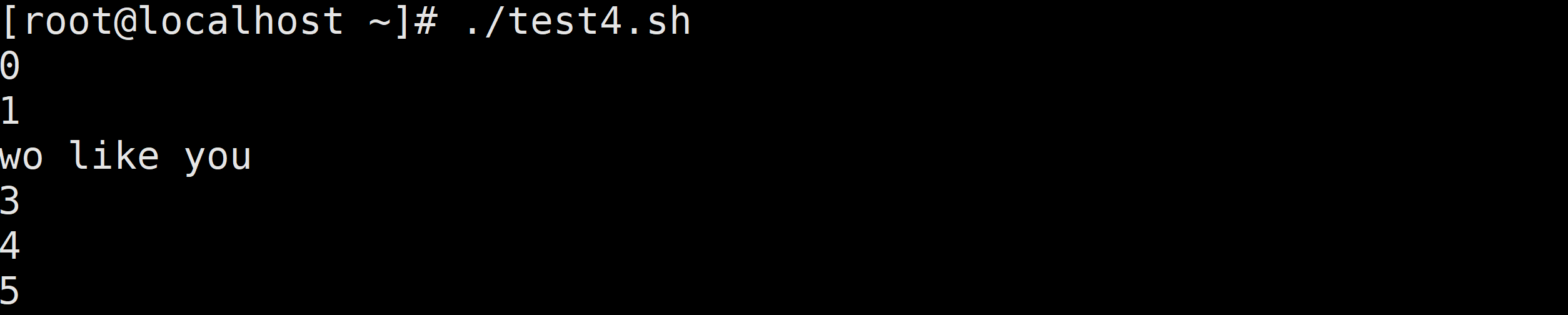
需求2:输出0-5之间的数字,遇到2的时候,输出“我喜欢你”(就不打印2了)(重点)

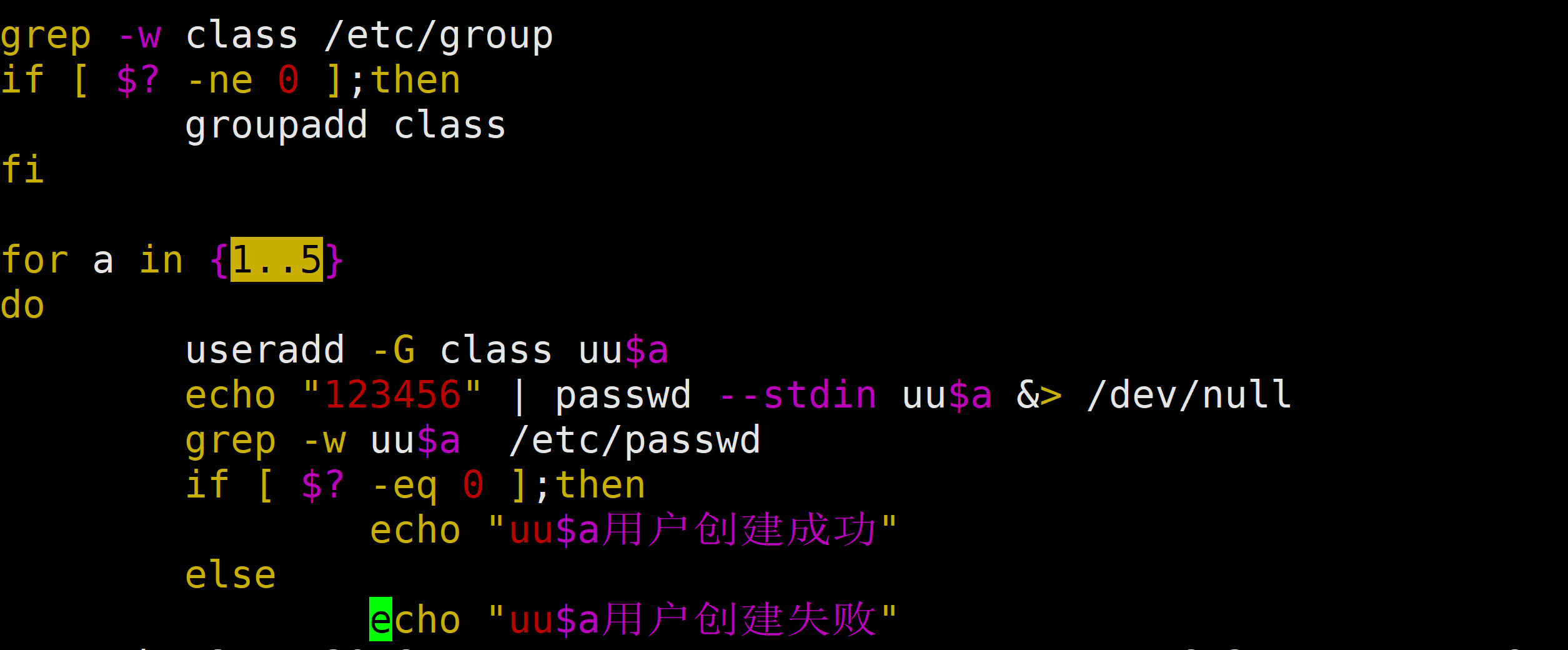
需求3:批量加5个新用户,以u1到u5命名,并统一加一个新组,组名为class,统一改密码为123
useradd -G class
echo "123" > passwd –stdin

需求4:批量新建5个用户stu1~stu5,要求这几个用户的家目录都在/rhome.提示:需要判断该目录是否存在
需求5:写一个脚本,局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里,这是一个局域网内机器检查通讯的一个思路(需要测试的IP缩小一下范围,只要测试10个IP即可),显示脚本运行的时间(执行脚本前加上time)
9.循环控制(continue,break,exit)
循环体: do….done之间的内容
- continue:继续;表示循环体内下面的代码不执行,重新开始下一次循环,跳过本次循环(本次循环体里面的代码不会执行)
- break:打断;马上停止执行本次循环,执行循环体后面的代码,退出循环,循环结束
- exit:表示直接跳出程序
正常状态:
需求:输出1-5之间的数字,遇到2的倍数的时候不打印,直接跳过
#!/bin/bash
for i in {1..5}
do
let temp=$i%2
if [ $temp -eq 0 ];then
continue
else
echo $i
fi
done
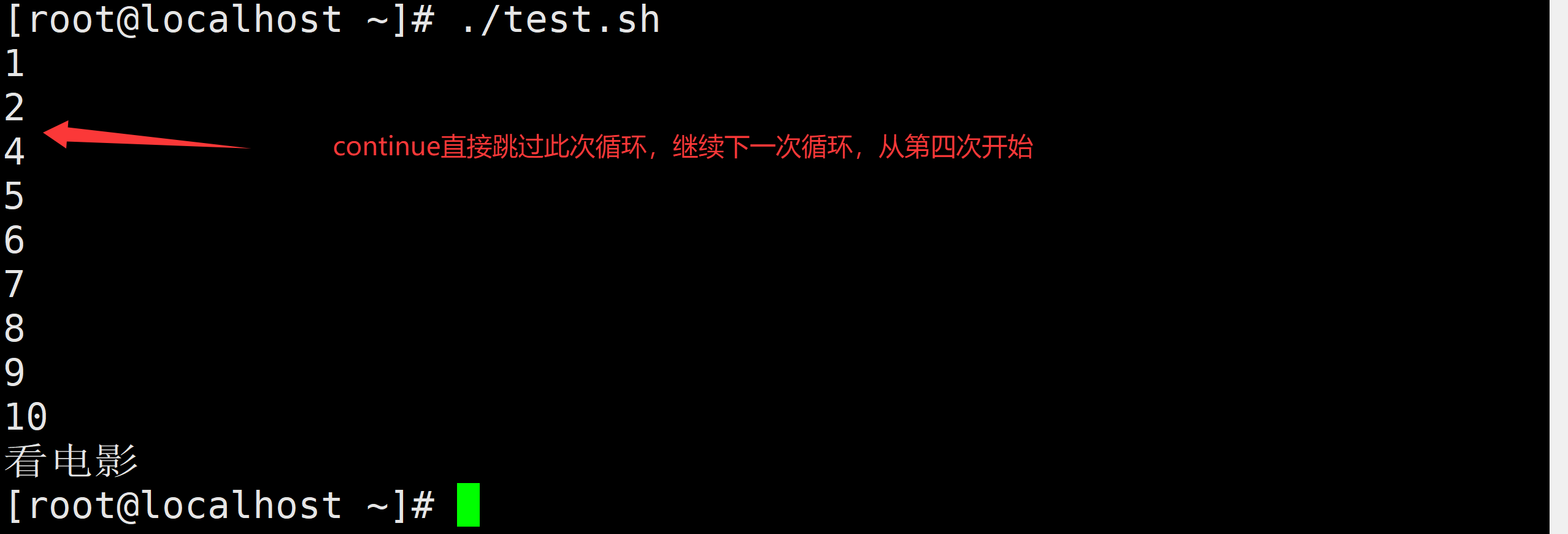
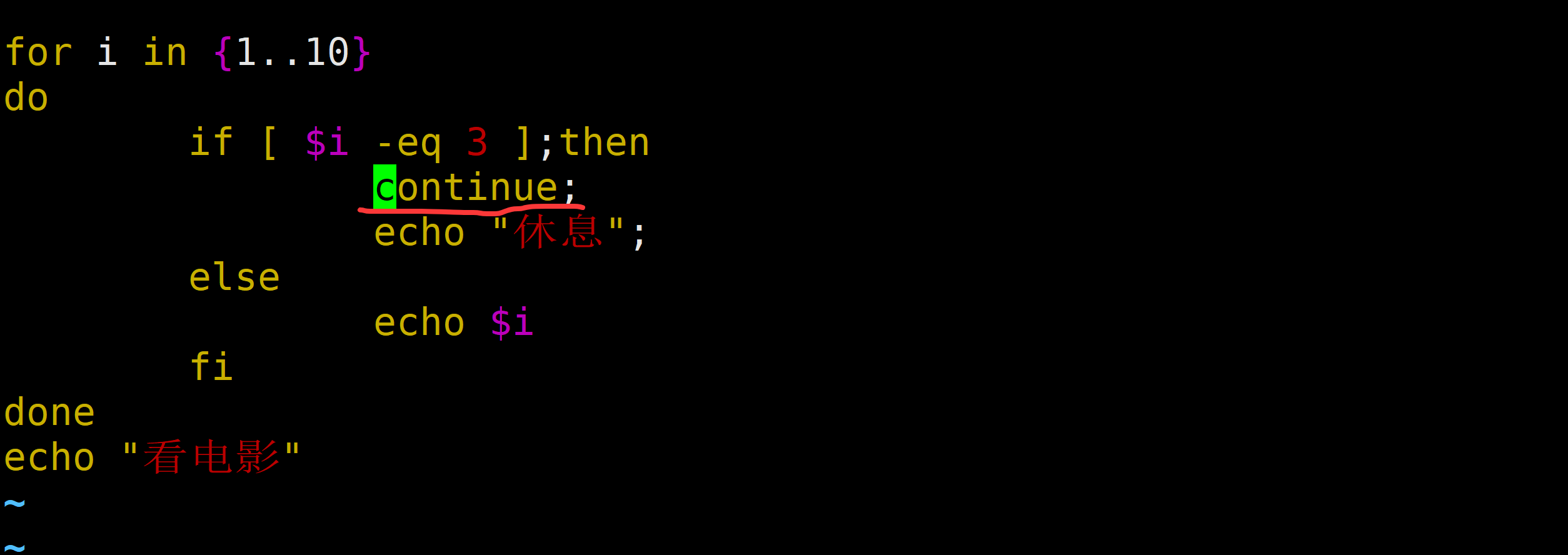
echo "哈哈,程序终于执行完了"需求:输出1-5之间的数字,遇到3的倍数的时候,直接结束循环
#!/bin/bash
for i in {1..5}
do
let temp=$i%3
if [ $temp -eq 0 ];then
break
else
echo $i
fi
done
echo "哈哈,程序终于执行完了"

需求:输出1-5之间的数字,遇到4的倍数的时候,直接退出程序
#!/bin/bash
for i in {1..5}
do
let temp=$i%3
if [ $temp -eq 0 ];then
exit
else
echo $i
fi
done
echo "哈哈,程序终于执行完了"

课堂练习:
需求:输出0-5之间的数字,遇到2的倍数的时候不打印,直接跳过
需求:输出0-5之间的数字,遇到3的倍数的时候,直接结束循环
需求:输出0-5之间的数字,遇到4的倍数的时候,直接退出程序小结
- for循环语法结构
- for循环可以结合条件判断和流程控制语句
- do ......done 循环体
- 循环体里可以是命令集合,再加上条件判断以及流程控制
- 控制循环语句
- continue 继续,跳过本次循环,继续下一次循环
- break 打断,跳出循环,执行循环体外的代码
- exit 退出,直接退出程序10.cut命令
1)概述
cut 命令用于从文件或标准输入中提取指定字段或字符位置的数据。它可以根据字段的分隔符将每行数据分割成多个字段,并选择需要提取的字段进行输出。cut 命令是一个简单而实用的工具,常用于处理文本文件中的数据。
2)语法
cut [选项]... [文件]...
-c: 以字符为单位进行分割
-d: 自定义分隔符,默认为制表符
-f: 与-d一起使用,指定显示哪个区域
# cut -d: -f1 1.txt 以:冒号分割,截取第1列内容
# cut -d: -f1,6,7 1.txt 以:冒号分割,截取第1,6,7列内容
# cut -c4 1.txt 截取文件中每行第4个字符
# cut -c1-4 1.txt 截取文件中每行的1-4个字符
# cut -c4-10 1.txt 截取文件中每行的4-10个字符
# cut -c5- 1.txt 从第5个字符开始截取后面所有字符 3)使用
需求:使用cut工具获取passwd文件中,只显示名称与UID,显示前五行

cd
cp /etc/passwd ./
cut -d: -f1,3 passwd | head -5
11.while循环
11.1 语法结构
特点:条件为真就进入循环;条件为假就退出循环
while 条件表达式
do
command...
done示例
i=1
while [ $i -le 5 ]
do
echo $i
let i++
done11.2课堂案例
需求1:使用while循环打印1-10之间的数字

需求2:获取用户输入的字符,用户输入什么,就打印什么,直到用户输入的是quit,则退出程序
运行结果:
#!/bin/bash
i=1
while [ $i -le 10 ]
do
echo $i
let i++
done
#!/bin/bash
i=10
while [ $i -ge 1 ]
do
echo $i
let i--
done
#!/bin/bash
i=1
while [ $i -le 10 ]
do
if [ $[ $i%2 ] -eq 0 ];then
let i++
continue
fi
echo $i
let i++
done
#!/bin/bash
i=1
while [ $i -le 10 ]
do
echi $i
let i++
done
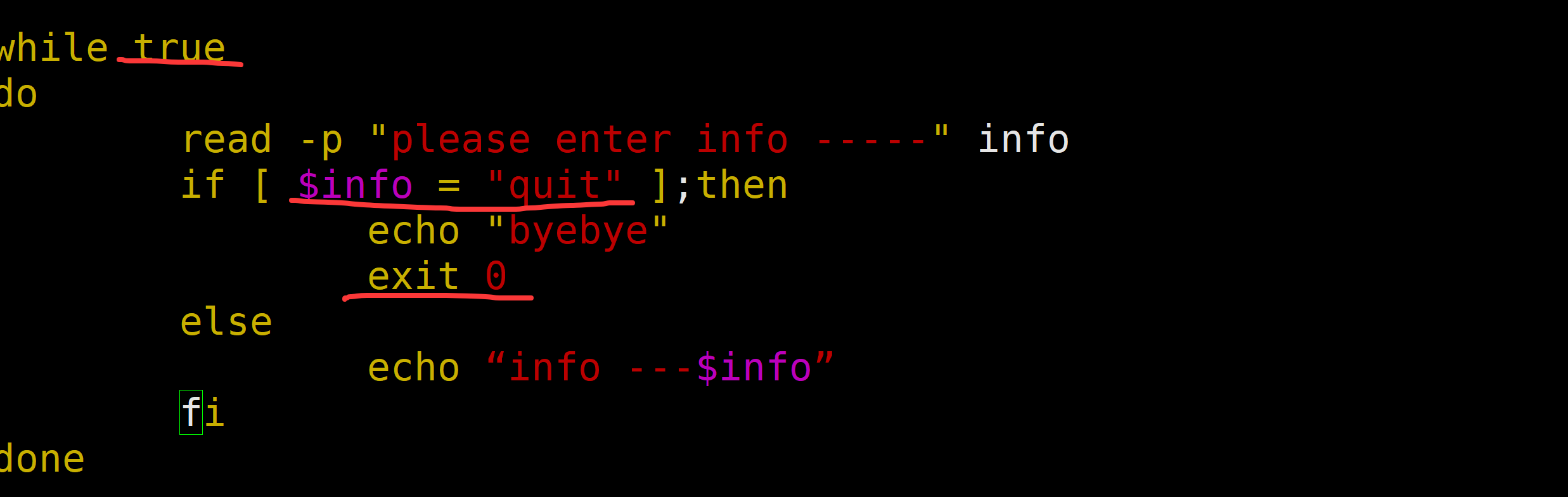
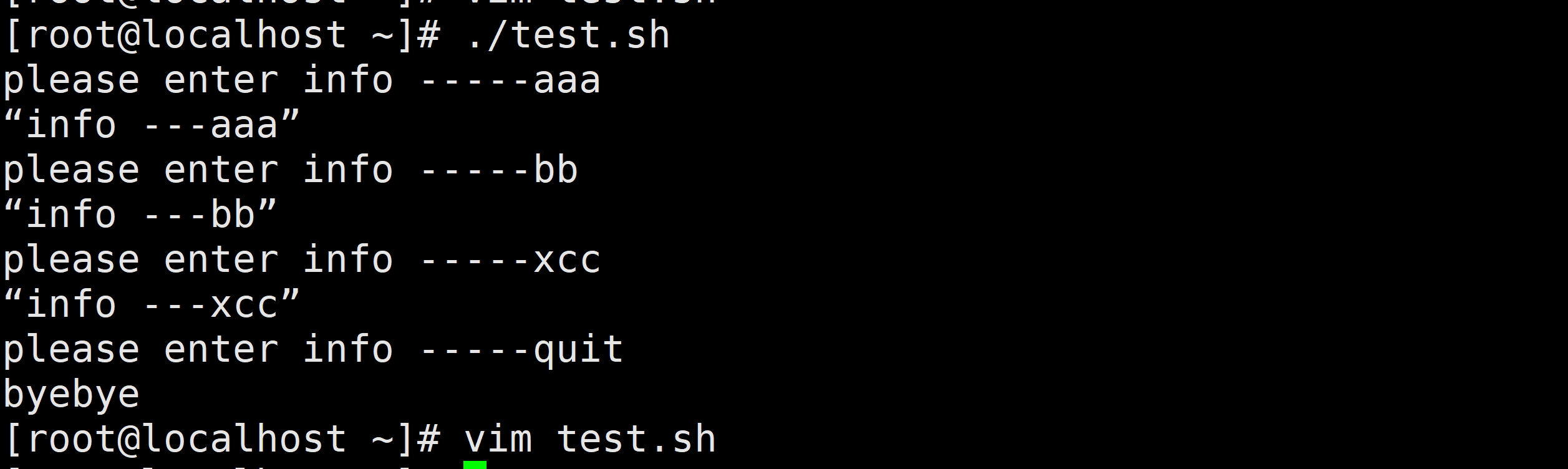
需求2:获取用户输入的字符,用户输入什么,就打印什么,直到用户输入的是quit,则退出程序
#! /bin/bash
echo “输入内容,直到quit退出-----”
while true
do
read info
if [ $info = "quit" ];then
echo "byebye"
exit 0
else
echo $info
fi
done
在 Shell 脚本中,exit 0 是一个用于终止脚本执行并返回状态码的命令。
0 是返回给父进程的状态码,表示脚本成功执行(约定俗成的 “成功” 状态)。需求2:写一个30秒同步一次时间,向同步服务器cn.ntp.org.cn同步时间,如果同步失败,则进行邮件报警,每次失败都报警;同步成功,也进行邮件通知,但是成功100次才通知一次。
ntpdate cn.ntp.org.cn 同步时间操作
echo “邮件内容” | mail -s “邮件主题” root@server
#!/bin/bash
# 定义一个计数器,用于统计时间同步成功的次数
count=0
# 时间同步时间是一直需要进行的,所以需要写一个死循环,每次同步时间间隔30秒,休眠30秒即可
while [ 1 -eq 1 ]
do
# 同步时间操作
ntpdate cn.ntp.org.cn
if [ $? -eq 0 ];then
# 同步成功,count的次数要加1
let $count++
# 同步成功还要看是否达到100次,或者100的倍数次
if [ $[ $count%3 ] -eq 0 ];then
# 发送邮件
echo "$(date "+%Y-%m-%d-%H:%M:%S")同步成功100次,发送邮件操作" | mail -s "时间同步" root@server
fi
else
echo "$(date "+%Y-%m-%d-%H:%M:%S")同步失败,发送邮件操作" | mail -s "时间同步" root@server
fi
donewhile循环的特殊用法
abc.txt
aaa 1
bbb 2
ccc 3
ddd 3
#/bin/bash
while read a b
do
echo $a:$b
done < abc.txt需求3:统计系统中有多少个管理员用户,多少个系统用户,多少个普通用户
- tr(translate 的缩写)是 Linux 系统中用于字符转换、替换或删除的强大命令。它通过标准输入读取数据,对字符进行逐字符处理,并将结果输出到标准输出。
- cut -d: -f1,3 /etc/passwd | tr ‘:’ ‘ ‘ > temp
#!/bin/bash
root_count=0
sys_count=0
other_count=0
# 1. 读取/etc/passwd文件 用户名 用户ID
cut -d: -f1,3 /etc/passwd | tr ':' ' ' > temp
tr(translate 的缩写)是 Linux 系统中用于字符转换、替换或删除的强大命令。它通过标准输入读取数据,对字符进行逐字符处理,并将结果输出到标准输出。
# 2. 循环判断用户的ID,以判断用户的类型
while read name uid
do
# 3. 使用计数器来统计不通类型用户的数量
if [ $uid -eq 0 ];then
let root_count++
elif [ $uid -ge 1 -a $uid -le 999 ];then
let sys_count++
else
let other_count++
fi
done < temp
echo "管理员用户的数量为:$root_count"
echo "系统用户的数量为:$sys_count"
echo "普通用户的数量为:$other_count"
12.随机数()$RANDOM
12.1 概述
随机数就是使用一个命令或者工具随机生成一个数字,带有一些不确定性
bash默认有一个$RANDOM的变量,通过这个变量可以产生随机数,随机数生成的范围默认是0~32767。
12.2 语法结构
产生0~1之间的随机数
echo $[$RANDOM%2]
产生0~9内的随机数
echo $[$RANDOM%10]
产生50-100之内的随机数
echo $[$RANDOM%51+50]
产生三位数的随机数
echo $[$RANDOM%900+100]
产生5-10之间的随机
echo $[$RANDOM%6+5]12.3 课堂案例
需求1:猜数字游戏;生成一个1-10之间的随机数,然后使用交互式的方式由用户输入一个数字,猜对了就提示win,猜错了就提示loss

需求2:写一个脚本,产生一个phone_num.txt文件,随机产生以139开头的手机号10个,每个一行

需求3:写一个脚本,产生一个phone_num.txt文件,随机产生以139开头的手机号100个,每个一行,还要求生成的手机号码不能重复
13.case语法
13.1 概述
case语法是对if的补充,使用 case 语句改写 if 多分支可以使脚本结构更加清晰、层次分明。针对变量的不同取 值,执行不同的命令序列。一般常用与菜单选项中,比如我们使用fdisk进行磁盘分区的时候,输入m是查看帮助,输入n是新建分区,输入w是保存分区,输入p是显示分区列表等
case语句为多选择语句。可以用case语句匹配一个值与一个模式,如果匹配成功,执行相匹配的命令

13.2 语法
case var in # 定义变量;var代表是变量名
pattern 1) # 模式1;用 | 分割多个模式,相当于or,所谓模式就一个具体的值
command1 # 需要执行的语句
;; # 两个分号代表命令结束
pattern 2)
command2
;;
pattern 3)
command3
;;
*) # default,不满足以上模式,默认执行*)下面的语句
command4
;;
esac # esac表示case语句结束需求:使用case模拟一个多分支的场景(1 —- 单身 2 —- 喜欢 3 —- 分手 4 —- 试一试 5-8 结婚 9 —- 退出)
#!/bin/bash
read -p "请输入一个1-9之间的数字:" num
echo "num的值为:$num"
case $num in
1)
echo "单身"
;;
2)
echo "喜欢"
;;
3)
echo "分手"
;;
4)
echo "试一试"
;;
5|6|7|8)
echo "结婚"
;;
9)
echo "bye"
;;
*)
echo "不要瞎搞"
;;
esac
echo "程序结束了"#!/bin/bash
while true
do
read -p "请输入一个1-9之间的数字:" num
case $num in
1)
echo "单身"
;;
2)
echo "喜欢"
;;
3)
echo "分手"
;;
4)
echo "试一试"
;;
5|6|7|8)
echo "结婚"
;;
9)
echo "bye"
exit
;;
*)
echo "不要瞎搞"
;;
esac
done13.3 课堂案例
需求1:按键类型识别
需求2:当给程序传入start、stop、reload三个不同参数时分别执行相应命令
需求3:模拟一个多任务维护界面。当执行程序时先显示总菜单,然后进行选择后做相应维护监控操作
14.函数
1.1 概述
shell中允许将一组命令集合或语句形成一段可用代码,这些代码块称为shell函数。给这段代码起个名字称为函数名,后续可以直接调用该段代码的功能
Shell 函数的本质是一段可以重复使用的脚本代码,这段代码被提前编写好了,放在了指定的位置,使用时直接调取即可
函数的特点:
- 函数不被调用不会被执行
- return表示退出函数并返回一个退出值,脚本中可以用$?变量显示该值,如果没有return。默认取决于函数中执行的最后一条命令的退出状态码
- 退出状态码必须是0~255,超出时值将为除以256取余。如果大于255的返回值,可以通过echo 返回
- 用 $? 来获取函数的 return值,用 $(函数名) 来获取函数的 echo值
1.2 函数的定义
语法格式一:
函数名()
{
函数体(一堆命令的集合,来实现某个功能)
}语法格式二:
function 函数名()
{
函数体(一堆命令的集合,来实现某个功能)
}

需求1:使用语法格式二定义个函数,用于计算两个数的和
#!/bin/bash
function sum()
{
a=5
b=4
return $[$a+$b]
}
sum
echo "使用函数sum计算两个数的和: $?"
#!/bin/bash
function sum()
{
a=251
b=5
return $[$a+$b]
}
sum
echo "使用函数sum计算两个数的和: $?"
#!/bin/bash
function sum()
{
a=251
b=5
echo $[$a+$b]
}
ss=$(sum)
echo "使用函数sum计算两个数的和: $ss"
需求2:使用语法格式二定义个函数,用于比较两个数的大小,两个数由参数传递进去
#!/bin/bash
function get_max()
{
if [ $# -lt 2 ];then
echo "参数错误"
return
fi
if [ $1 -eq $2 ];then
echo "相等"
elif [ $1 -gt $2 ];then
echo "大于"
else
echo "小于"
fi
}
result=$(get_max 1 2)
echo "使用函数get_max的结果为: $result"
1.3 函数的调用
1)shell脚本内部调用
在之前的案例中,使用的都是脚本内调用的方式,这样的方式,存在的问题,就是这个函数只能在这个shell脚本中使用,其它脚本就不能使用了
#!/bin/bash
function sum()
{
a=5
b=4
return $[$a+$b]
}
sum
echo "使用函数sum计算两个数的和: $?"2)终端调用
通过source引入脚本文件使用
定义一个脚本函数:fun.sh
#!/bin/bash
test1()
{
echo "我是fun.sh.sh文件中的test1函数"
}
test2()
{
echo "我是fun.sh.sh文件中的test2函数"
}
定义一个需要执行的脚本:5.sh
#!/bin/bash
source /root/fun.sh
test1



3)全局调用
全局调用就是将函数定义到全局文件中,如:~/.bashrc 或者 /etc/bashrc
需求:在/etc/bashrc定义一个函数,在脚本中调用使用
注意:需要将以下脚本添加到/etc/bashrc文件中。然后使用source /etc/bashrc重新读取文件
function test3()
{
echo "在/etc/bashrc定义的test3函数"
}定义一个需要执行的脚本:6.sh
:wq#!/bin/bash
source /etc/bashrc
test31.4 课堂案例
需求:使用函数的方式判断一个url是否正常
#!/bin/bash
# 如果可以ping通,返回该地址可用,如果ping不同,返回该地址不可用
function check_url(){
# 获取参数,判断该地址是否可以ping通
ping -c1 $1 &> /dev/null
if [ $? -eq 0 ];then
echo "$1:地址可用"
else
echo "$1:地址不可用"
fi
}
# 交互式输入一个数据
read -p "请输入一个url地址:" url
# 调用函数,并且将url传递给函数
result=$(check_url $url)
# 打印结果
echo $result15.正则表达式
15.1 概述
在Linux系统中,Shell正则表达式是一种强大的文本处理工具,它允许用户通过模式匹配来检索和操作文本。正则表达式由普通字符和元字符组成,其中元字符具有特殊意义,用于规定其前导字符在目标对象中的出现模式。在Linux中,常用的正则表达式引擎有两种:基础正则表达式(BRE)和扩展正则表达式(ERE)。
Shell正则表达式是一种强大的文本处理工具,它允许用户通过模式匹配来检索和操作文本,在Linux系统中广泛用于文本分析和处理任务
15.2 语法
1)名词解释
元字符:指那些在正则表达式中具有特殊意义的专用字符,如:点(.) 星(*) 问号(?)等
前导字符:即位于元字符前面的字符
2)语法概述
(1). 任意单个字符,除了换行符
(2)* 前导字符出现0次或连续多次 ab*能匹配“a”,“ab”以及“abb”,但是不匹配“cb”
(3).* 任意长度的字符 ab.* ab123 abbb abab
(4)^ 行的开头
(5)$ 行的结尾
(6)^$ 空行
(7)[] 匹配指定字符组内的任一单个字符 [abc]
(8)[^] 匹配不在指定字符组内的任一字符 [^abc]
(9)^[] 匹配以指定字符组内的任一字符开头 ^[abc]
(10)^[^] 匹配不以指定字符组内的任一字符开头 ^[^abc]
(11)\< 取单词的头
(12)\> 取单词的尾
(13)\<\> 精确匹配符号 grep -w 'xxx'
(14)\{n\} 匹配前导字符连续出现n次 go\{2\} google gooogle
(15)\{n,\} 匹配前导字符至少出现n次 go\{2,\} google gooogle
(16)\{n,m\} 匹配前导字符出现n次与m次之间
(17) \(strings\) 保存被匹配的字符15.3 课堂案例
前提,创建一个abc.txt文件,往文件中添加如下数据:
ggle
gogle
google
gooogle
goooooogle
gooooooogle
taobao.com
taotaobaobao.com
aaab
abc
ac
bc
abbc
abab
jingdong.com
dingdingdongdong.com
192.168.217.129
192.168.217.1
192.168.217
Adfjd8789JHfdsdf/
a87fdjfkdLKJK
7kdjfd989KJK;
bSKJjkksdjf878.
cidufKJHJ6576,
heihei
hello world
helloworld yourself
heihellow hello需求1:请描述以下命令得到的结果是:grep go* grep goo* grep ab.* grep ab*
grep go* : 包含g字符的含,其中o字符和已出现0次或者多次(o为前导字符)
grep goo* : 包含go字符的含,其中第二个o字符和已出现0次或者多次(第二个o为前导字符)
grep ab.* : 包含ab字符的含
grep ab* : 包含a字符的含,其中b字符和已出现0次或者多次(b为前导字符)需求2:请找出以go开头的行
grep ^go abc.txt
需求3:请找出以.com结尾的行
grep .com$ abc.txt
需求4:请找出文件中哪些行是空行,并显示行号
grep -n ^$ abc.txt
cat -n abc.txt
需求5:请找出文件中包含abc中任意一个字符的行
grep [abc] abc.txt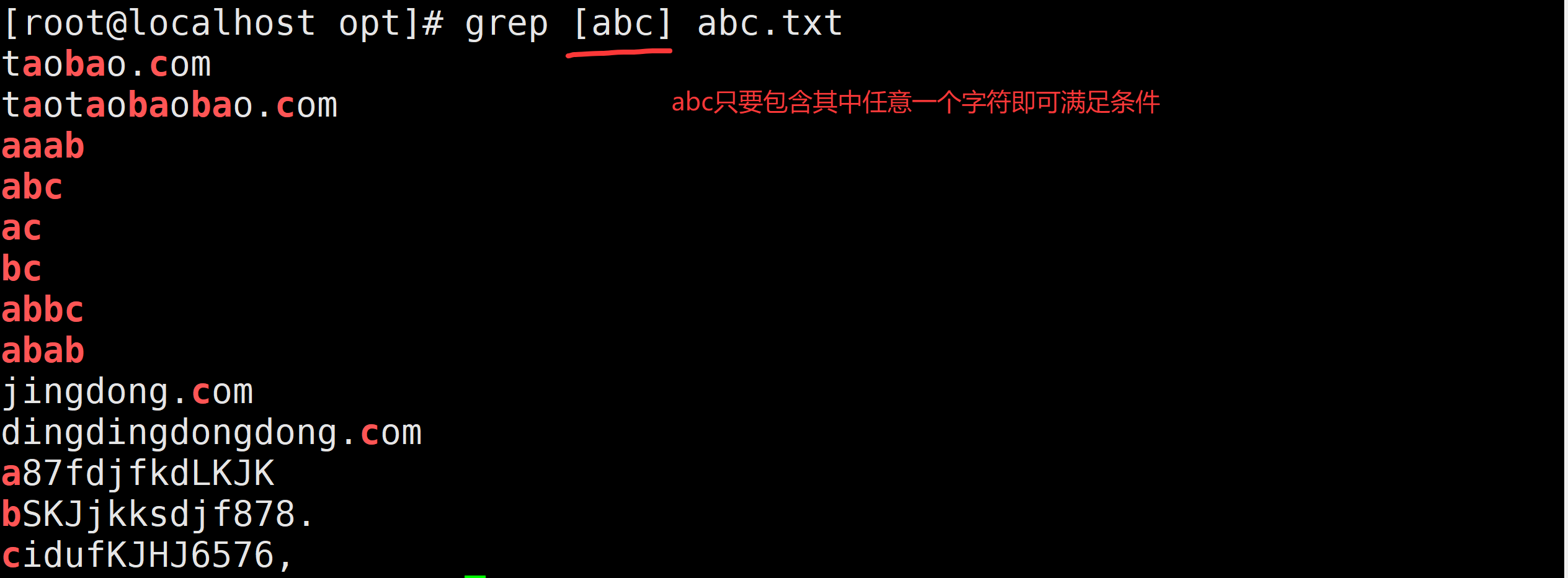
需求6:请找出以hel开头的单词
grep "\<hel" abc.txt
需求7:请找出以hei结尾的单词
grep "hei\>" abc.txt
需求8:精确查找包含hello单词的行
grep "\<hello\>" abc.txt
grep -w hello abc.txt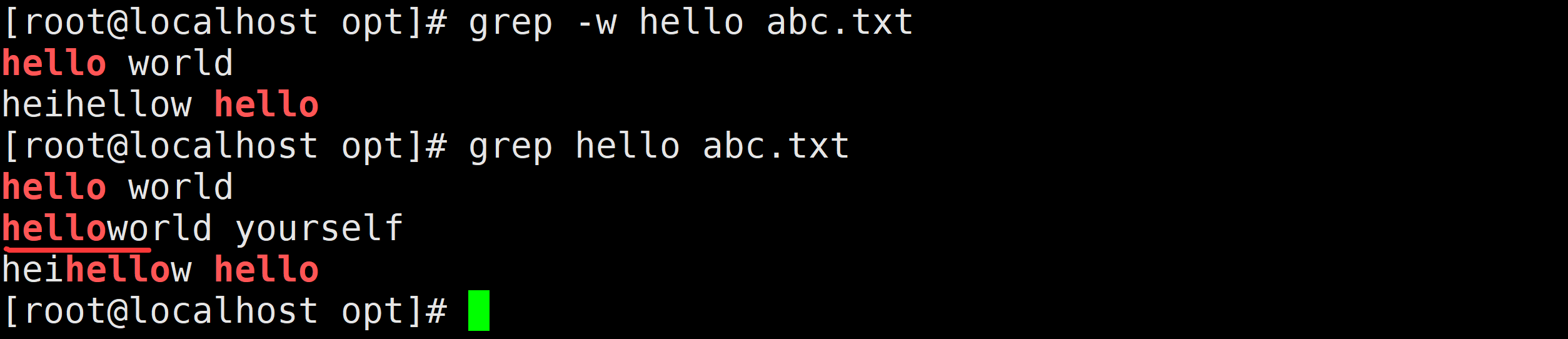
需求9:请描述以下命令得到的结果是:grep go*\{2\} grep go*\{2,\} grep go*\{2,3\}
grep 'go\{2\}' : 前导字符o出现两次
grep 'go\{2,\}' : 前导字符o出现两次以上
grep 'go\{2,3\}' : 前导字符o出现两次或者3次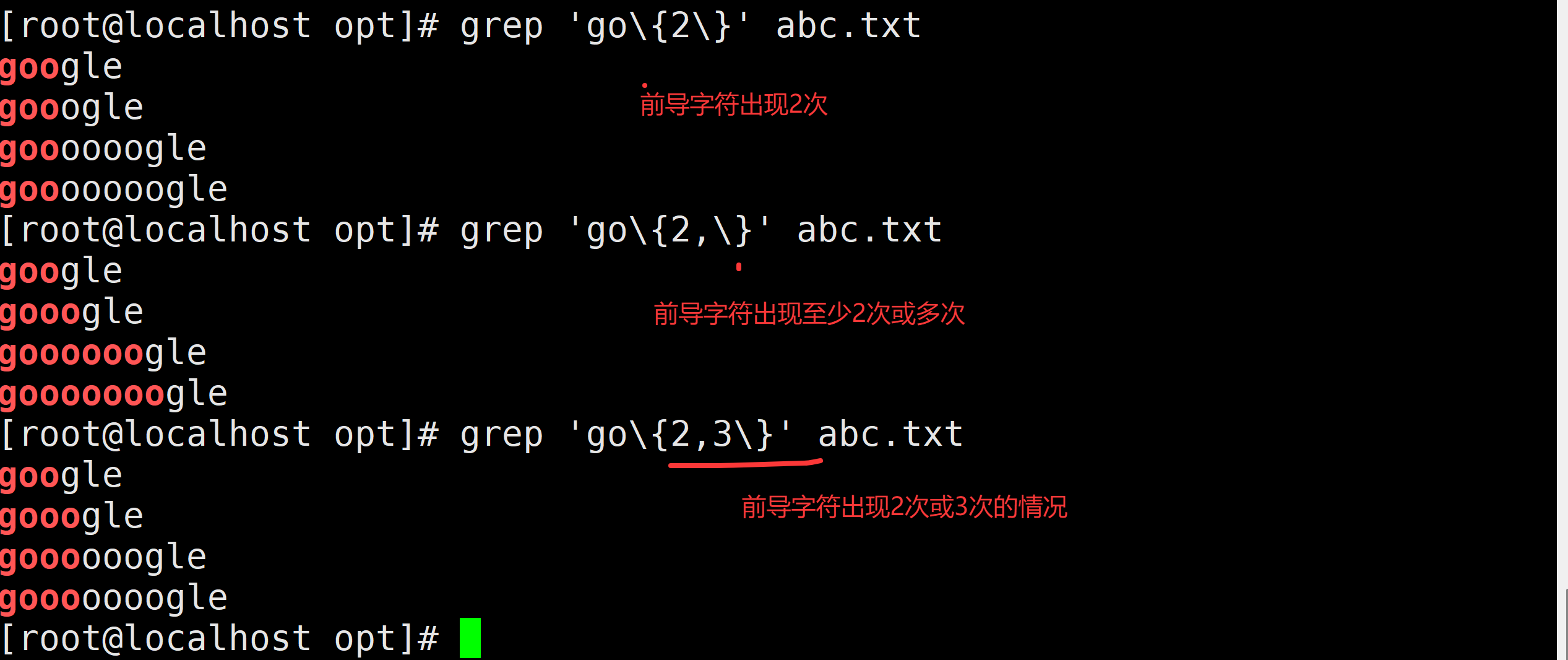
需求10:将192.168.217.129替换成192.168.217.130
vim abc.txt
:%s/192.168.217.129/192.168.217.130/g
或者
:%s#192.168.217.129#192.168.217.130#g
% -- 表示对所有行进行操作(若省略则仅对当前行生效)
s:替换(substitute)命令。
192.168.217.129 - 旧内容
192.168.217.130 - 新内容
g -- 全局替换,会替换这一行出现的所有匹配的字符,不加的话只替换第一个vim abc.txt
:%s#\(192.168.217\).129#\1.130#g需求11:将helloworld yourself 换成hellolilei myself
vim abc.txt
:%s#\(hello\)world your\(self\)#\1lilei my\2#g需求1:请描述以下命令得到的结果是:`grep go*` `grep goo*` `grep ab.*` `grep ab*`
需求2:请找出以`go`开头的行
需求3:请找出以`.com`结尾的行
需求4:请找出文件中哪些行是空行,并显示行号
需求5:请找出文件中包含`abc`中任意一个字符的行
需求6:请找出以`hel`开头的单词
需求7:请找出以`hei`结尾的单词
需求8:精确查找包含`hello`单词的行
需求9:请描述以下命令得到的结果是:`grep go*\{2\}` `grep go*\{2,\}` `grep go*\{2,3\}`
需求10:将192.168.217.129替换成192.168.217.130
需求11:将helloworld yourself 换成hellolilei myselfPerl内置正则:
\d 匹配数字 [0-9]
\w 匹配字母数字下划线[a-zA-Z0-9_]
\s 匹配空格、制表符、换页符[\t\r\n]
备注:普通正则中可以使用:[0-9] [a-z] [A-Z] [a-zA-Z] [a-Z]
备注:使用Perl内置正则,需要添加选项-P需求1:找出包含数字的行
grep [0-9] abc.txt
grep -P "\d" abc.txt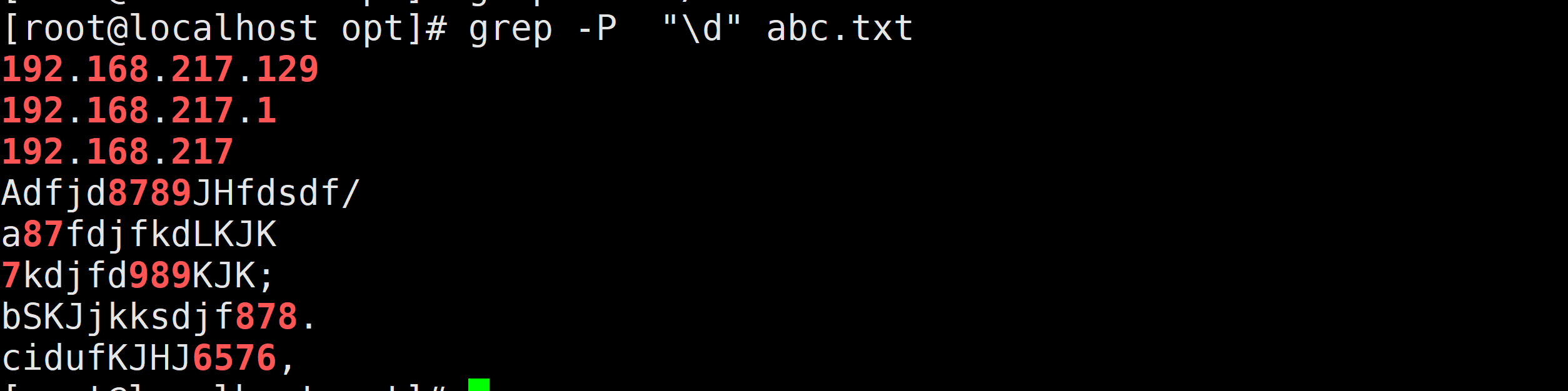
需求2:找出包含ip的行
grep "[0-9]\{3\}\.[0-9]\{3\}\.[0-9]\{3\}\.[0-9]\{1,3\}" abc.txt
grep -P "\d\{3\}.\d\{3\}.\d\{3\}.\d\{1,3\}" abc.txt
grep -P "\d"\{3\}\."\d"\{3\}\."\d"\{3\}\."\d"\{1,3\} abc.txt需求1:找出包含数字的行
需求2:找出包含ip的行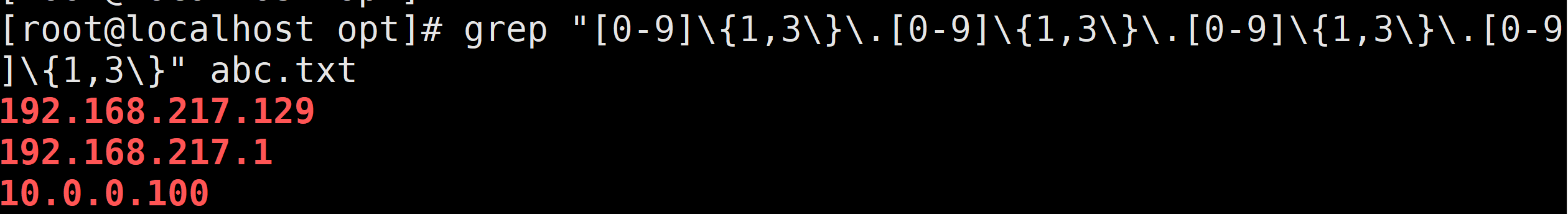
扩展类的正则表达式 grep -E 或则 egrep
扩展正则表达式元字符
+ 匹配一个或多个前导字符 bo+ boo bo
? 匹配零个或一个前导字符 bo? b bo
a|b 匹配a或b [ab]
() 组字符 hello myself yourself (my|your)self
{n} 前导字符重复n次 \{n\}
{n,} 前导字符重复至少n次 \{n,\}
{n,m} 前导字符重复n到m次 \{n,m\}需求:找出包含ip的行
grep -E "[0-9]{3}\.[0-9]{3}\.[0-9]{3}\.[0-9]{1,3}" abc.txt
grep -E "([0-9]{3}\.){3}[0-9]{1,3}" abc.txt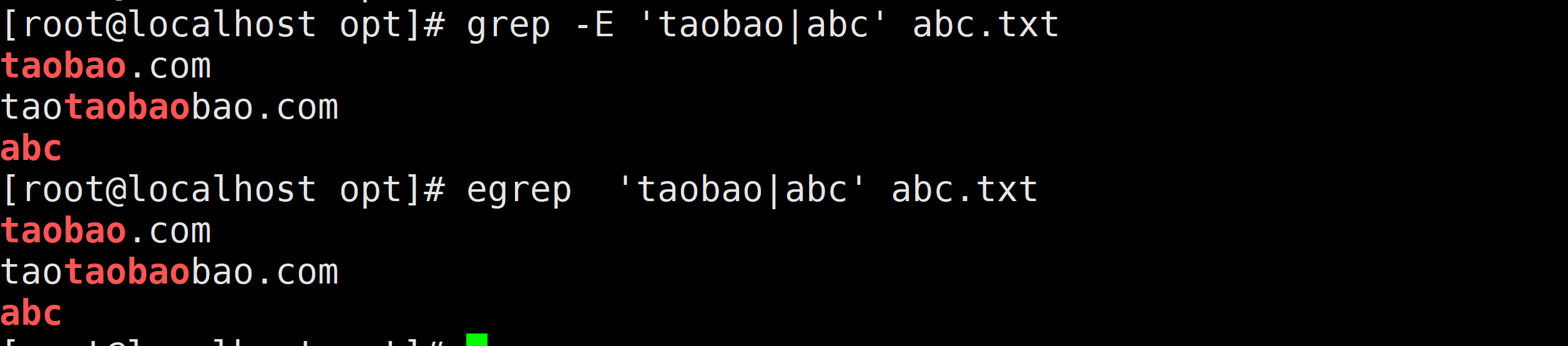
15.4 课堂练习
Aieur45869Root0000
9h847RkjfkIIIhello
rootHllow88000dfjj
8ikuioerhfhupliooking
hello world
192.168.0.254
welcome to uplooking.
abcderfkdjfkdtest
rlllA899kdfkdfj
iiiA848890ldkfjdkfj
abc
12345678908374
123456@qq.com
123456@163.com
abcdefg@woniu.com23ed1、查找不以大写字母开头的行
grep -v ^[A-Z] www.txt
grep ^[^A-Z] www.txt
2、查找有数字的行
grep [0-9] www.txt
3、查找一个数字和一个字母连起来的
grep '[0-9][a-zA-Z]\+\|[a-zA-Z][0-9]\+'
4、查找不以r开头的行
grep -v ^r www.txt
5、查找以数字开头的
grep ^[0-9] www.txt
6、查找以大写字母开头的
grep ^[A-Z]
7、查找以小写字母开头的
grep ^[a-z]
8、查找以点结束的
grep [.]$
9、去掉空行
grep -v ^$
egrep -v '^$|^#' /etc/ssh/sshd_config
10、查找完全匹配abc的行
grep -w abc www.txt
11、查找A后有三个数字的行
grep 'A[0-9]\{3\}' www.txt
12、统计root在/etc/passwd里出现了几次
grep -o root /etc/passwd | wc -l
13、用正则表达式找出IP地址16.shell三剑客
shell三剑客是grep、sed和awk三个工具的简称,因功能强大,使用方便且使用频率高,因此被戏称为三剑客,熟练使用这三个工具可以极大地提升运维效率
| 命令 | 特点 | 使用场景 |
|---|---|---|
| grep | 擅长查找过滤 | 快速查找过滤 |
| sed | 擅长取行和替换 | 需要快速进行替换/修改文件内容 |
| awk | 擅长取列、统计计算 | 文件取列、数据切片、对比/比较和统计 |
17.shell三剑客之一grep
3.1 概述
grep是文本查找或搜索工具,用于查找内容包含指定的范本样式的文本。它会一行一行循环匹配,匹配到相应的值时会先输出,然后换行继续匹配再换行直到所有的内容都匹配完
3.2 语法
命令:grep
作用:行过滤
语法:grep [选项] 文件名称
选项参数:
-i: 不区分大小写 ---------
-v: 查找不包含指定内容的行,反向选择 ---------
-w: 按单词搜索 ---------
-o: 打印匹配关键字
-c: 统计匹配到的次数
-f:从文件每一行获取匹配模式
-n: 显示行号 -----------
-r: 逐层遍历目录查找
-A: 显示匹配行及后面多少行
-B: 显示匹配行及前面多少行
-C: 显示匹配行前后多少行
-l:只列出匹配的文件名
-L:列出不匹配的文件名
-e: 使用正则匹配 --------
-E:使用扩展正则匹配 ----------
^key:以关键字开头
key$:以关键字结尾
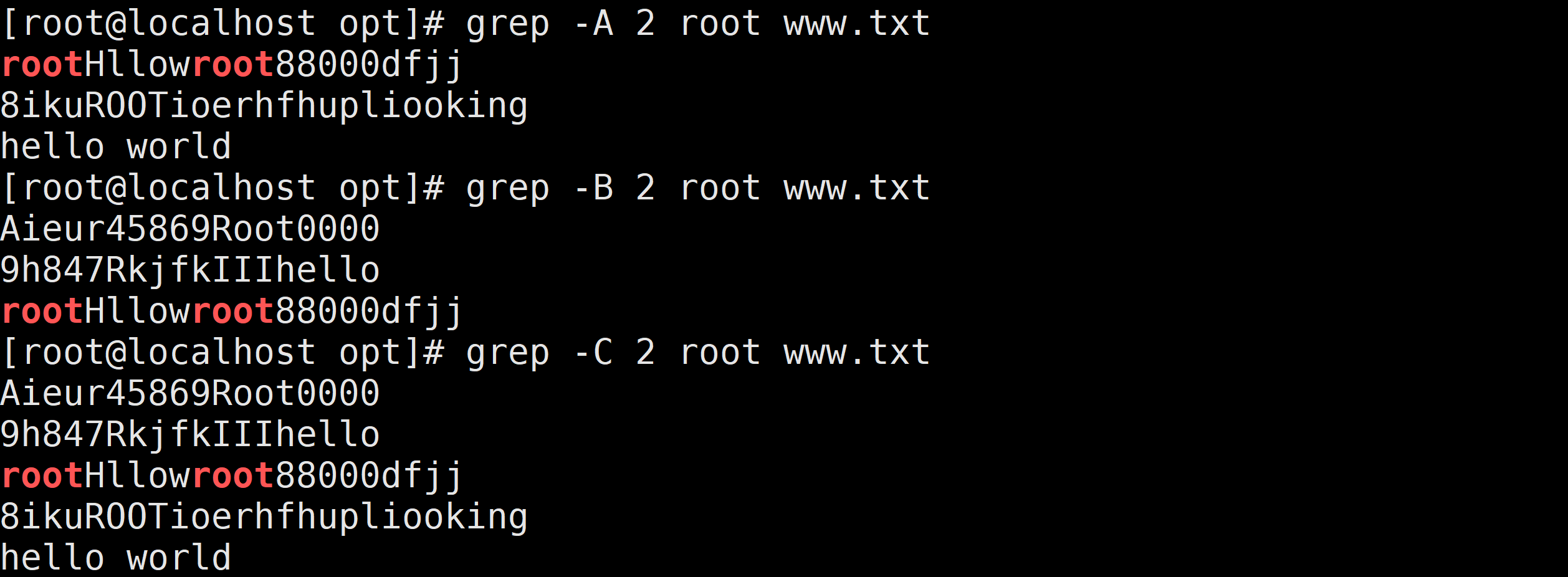
^$:匹配空行-i选项

3.3 课堂案例
示例:
# grep -i root passwd 忽略大小写匹配包含root的行
# grep -w ftp passwd 精确匹配ftp单词
# grep -w woniu passwd 精确匹配woniu单词
# grep -wo ftp passwd 打印匹配到的关键字ftp
# grep -n root passwd 打印匹配到root关键字的行号
# grep -ni root passwd 忽略大小写匹配统计包含关键字root的行
# grep -nic root passwd 忽略大小写匹配统计包含关键字root的行数
# grep -i ^root passwd 忽略大小写匹配以root开头的行
# grep bash$ passwd 匹配以bash结尾的行
# grep -n ^$ passwd 匹配空行并打印行号
# grep ^# /etc/vsftpd/vsftpd.conf 匹配以#号开头的行
# grep -v ^# /etc/vsftpd/vsftpd.conf 匹配不以#号开头的行
# grep -A 5 mail passwd 匹配包含mail关键字及其后5行
# grep -B 5 mail passwd 匹配包含mail关键字及其前5行
# grep -C 5 mail passwd 匹配包含mail关键字及其前后5行前提:创建a.txt及b.txt文件
touch a.txt
touch b.txt
echo woniu >> a.txt
echo woniuxy >> a.txt
echo abc >> a.txt
echo woniu >> b.txt
echo hello >> b.txt需求1:查找a.txt及b.txt文件中相同的内容woniu
grep -win "woniu" a.txt b.txt需求2:查找a.txt及b.txt文件中相同的行
grep -nw -f a.txt b.txt
需求3:查找a.txt及b.txt文件中不相同的行
grep -nwv -f a.txt b.txt
18.shell三剑客之一sed
18.1 概述
sed 是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(patternspace ),接着用sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使诸如‘D’ 的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出或-i功能:主要用来自动编辑一个或多个文件, 简化对文件的反复操作
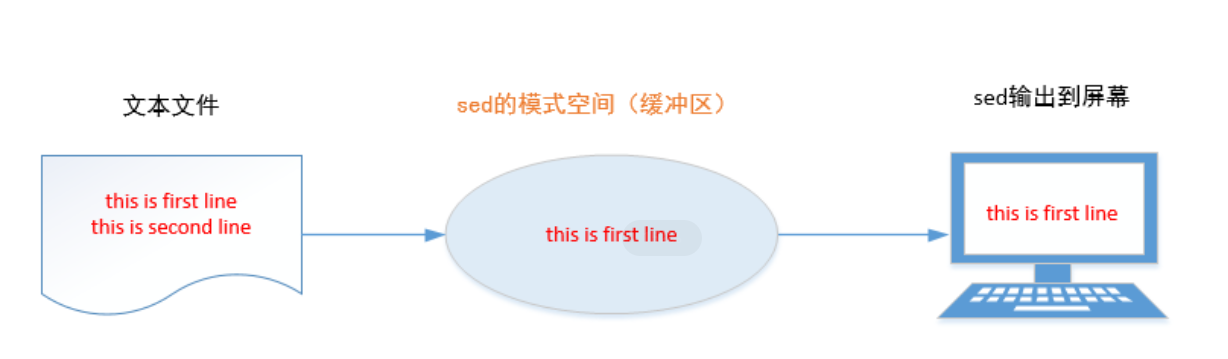
- 首先sed把当前正在处理的行保存在一个临时缓存区中(称为模式空间),然后处理临时缓冲区中的行,完成后把该行发送到屏幕上
- sed把每一行都存在临时缓冲区中,对这个副本进行编辑,所以不会修改原文件
- sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等
18.2 语法
sed常见的语法格式有两种,一种叫命令行模式,另一种叫脚本模式
命令:sed
作用:文件编辑
语法:sed [选项] 'sed的命令|地址定位' 文件名称
选项参数:
-e:进行多项编辑,即对输入行应用多条sed命令时使用
-n:取消默认的输出
-f:指定sed脚本的文件名
-r:使用扩展正则表达式
-i:inplace,原地编辑(修改源文件) 注意:使用-i选项是,不能使用-n及p命令
常用命令:
p:打印行数据
d:删除行数据
i\:在当前行之前插入文本。多行时除最后一行外,每行末尾需用"\"续行
a\:在当前行后添加一行或多行。多行时除最后一行外,每行末尾需用“\”续行
c\:用此符号后的新文本替换当前行中的文本。多行时除最后一行外,每行末尾需用"\"续行 整行替换
r:从文件中读取输入行
w:将所选的行写入文件
!:对所选行以外的所有行应用命令,放到行数之后
s:用一个字符串替换另一个
g:在行内进行全局替换
&:保存查找串以便在替换串中引用 \(string\)
=:打印行号注意:sed使用的正则表达式是括在斜杠线”/正则表达式/“之间的模式
sed和正则的综合运用
1、正则表达式必须以”/“前后规范间隔
例如:sed '/root/d' file
例如:sed '/^root/d' file
2、如果匹配的是扩展正则表达式,需要使用-r选来扩展sed
grep -E
sed -r
+ ? () {n,m} | \d
注意:
在正则表达式中如果出现特殊字符(^$.*/[]),需要以前导 "\" 号做转义
eg:sed '/\$foo/p' file
3、逗号分隔符
例如:sed '5,7d' file 删除5到7行
例如:sed '/root/,/ftp/d' file
删除第一个匹配字符串"root"到第一个匹配字符串"ftp"的所有行本行不找 循环执行
4、组合方式
例如:sed '1,/foo/d' file 删除第一行到第一个匹配字符串"foo"的所有行
例如:sed '/foo/,+4d' file 删除从匹配字符串”foo“开始到其后四行为止的行
例如:sed '/foo/,~3d' file 删除从匹配字符串”foo“开始删除到3的倍数行(文件中)
例如:sed '1~5d' file 从第一行开始删每五行删除一行
例如:sed -nr '/foo|bar/p' file 显示配置字符串"foo"或"bar"的行
例如:sed -n '/foo/,/bar/p' file 显示匹配从foo到bar的行
例如:sed '1~2d' file 删除奇数行
例如:sed '0-2d' file 删除偶数行 sed '1~2!d' file
5、特殊情况
例如:sed '$d' file 删除最后一行
例如:sed '1d' file 删除第一行
6、其他:
sed 's/.//' a.txt 删除每一行中的第一个字符
sed 's/.//2' a.txt 删除每一行中的第二个字符
sed 's/.//N' a.txt 从文件中第N行开始,删除每行中第N个字符(N>2)
sed 's/.$//' a.txt 删除每一行中的最后一个字符前提:创建一个文件abc.txt,在文件中添加如下数据:
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm root:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
298374837483
192.168.217.129
10.1.1.1
disable=YES需求1:使用p命令打印abc.txt中的所有内容
sed 'p' abc.txt需求2:使用-n选项,p命令打印abc.txt中的所有内容
sed -n 'p' abc.txt需求3:打印第1行内容
sed -n '1p' abc.txt需求4:打印第1行到第5行内容
sed -n '1,5p' abc.txt需求5:打印最后1行内容
sed -n '$p' abc.txt需求6:删除第1行内容
sed -n '1d' abc.txt
sed '1d' abc.txt需求7:删除最后1行内容
sed '$d' abc.txt需求8:删除第1行到第3行内容
sed '1,3d' abc.txt需求9:在第1行的后面添加hello
sed '1ahello' abc.txt需求10:在第5行的前面添加world
sed '5iworld' abc.txt需求11:将第1行的内容替换为hello world
sed '1chello world' abc.txt需求12:将/etc/hosts文件中的内容添加到第3行之后
sed '3r /etc/hosts' abc.txt需求13:将abc.txt文件中的第1行到第3行写入到文件a.txt中
sed '1,3w a.txt' abc.txt需求14:将abc.txt中包含root字符的行写入到文件a.txt中
sed '/root/w a.txt' abc.txt需求15:将包含abc.txt中包含数字的行写入到文件a.txt中
sed '/[0-9]/w a.txt' abc.txt需求16:将abc.txt中的第一个root替换为ROOT
sed 's/root/ROOT/' abc.txt需求17:将abc.txt中的所有root替换为ROOT
sed 's/root/ROOT/g' abc.txt需求18:将abc.txt中的所有/sbin/nologin 替换为 /bin/bash
sed 's#/sbin/nologin#/bin/bash#g' abc.txt需求19:将abc.txt中的空行替换掉
sed '/^$/d' abc.txt需求20:将abc.txt中的第1行到第3行注释掉
sed '1,3s/^/#/' abc.txt需求21:注释掉以root开头或者以lp开头的行
sed -r 's/^root|^lp/#&/' abc.txt需求22:打印以bash结尾的行的行号
sed -n '/bash$/=' abc.txt需求23:打印以以root开头或者lp开头的行,并且打印行号
sed -n -r '/^root|^lp/=' abc.txt需求24:在abc.txt文件中的第5行的前面插入“hello world”;在abc.txt文件的第3行下面插入“哈哈哈哈”
sed -e '5ihello world' -e '3a哈哈哈哈' abc.txt需求25:将abc.txt中的所有root替换为ROOT,修改源文件
sed -i 's/root/ROOT/g' abc.txt需求26:将abc.txt中的disable=YES替换为disable=NO,修改源文件
sed -i 's/disable=YES/disable=NO/' abc.txt18.3 课堂案例
需求1:过滤vsftpd.conf文件中以#开头的行和空行
grep -Ev "^#|^$" /etc/vsftpd/vsftpd.conf
sed -r '/^#|^$/d' /etc/vsftpd/vsftpd.conf需求2:过滤ifconfig ens33命令结果中的IP
ifconfig ens33 | sed -nr '/[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}/p' | sed -r 's/[a-z]|[A-Z]//g'
ifconfig ens33 | sed -nr '/[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}/p' | sed -r 's/[a-z]|[A-Z]//g' | sed 's/ /\n/g' | sed '/^$/d'18.4 课堂练习
前提:将/etc/passwd文件中的前面20行复制到本地目录中a.txt文件中
sed '1,20w a.txt' /etc/passwd需求1:将a.txt任意数字替换成空
sed 's/[0-9]/ /g' a.txt需求2:去a.txt掉文件1-5行中的数字、冒号、斜杠
sed -r '1,5s/[0-9]|:|\///g' a.txt | head -5需求3:匹配root关键字替换成hello woniu,并保存到test.txt文件中
sed -e 's/root/hello woniu/g' -e 'w test.txt' abc.txt需求4:删除vsftpd.conf配置文件里所有注释的行及空行(不要直接修改原文件)
sed -r '/^#|^$/d' /etc/vsftpd/vsftpd.conf需求5:使用sed命令截取自己的ip地址
需求6:使用sed命令一次性截取ip地址、广播地址、子网掩码
需求7:注释掉文件的2-3行和匹配到以root开头或者以ftp开头的行
sed '2,3s/^/#/' a.txt | sed -r 's/^root|^ftp/#&/'19.shell三剑客之一awk
1、awk基础
1.1 概述
awk是一种编程语言,主要用于在linux/unix下对文本和数据进行处理,是linux/unix下的一个工具。数据可以来自标准输入、一个或多个文件,或其它命令的输出。
awk的处理文本和数据的方式:逐行扫描文件,默认从第一行到最后一行,寻找匹配的特定模式的行,并在这些行上进行你想要的操作。
awk分别代表其作者姓氏的第一个字母。因为它的作者是三个人,分别是Alfred Aho、Brian Kernighan、Peter Weinberger。
gawk是awk的GNU版本,它提供了Bell实验室和GNU的一些扩展。
下面介绍的awk是以GNU的gawk为例的,在linux系统中已把awk链接到gawk,所以下面全部以awk进行介绍。

1.2 使用方式
命令:awk
作用:文本和数据进行处理
语法:awk [选项] 'commands' 文件名称
选项参数:
-F:定义字段分割符号,默认的分隔符是空格
-v:定义变量并赋值命名部分(commands)
正则表达式,地址定位
示例:
'/root/{awk语句}' sed中: '/root/p'
'NR==1,NR==5{awk语句}' sed中: '1,5p'
'/^root/,/^ftp/{awk语句}' sed中:'/^root/,/^ftp/p'
{awk语句1;awk语句2;...}
示例:
'{print $0;print $1}' sed中:'p'
'NR==5{print $0}' sed中:'5p'
注:awk命令语句间用分号间隔
BEGIN...END....
示例:
'BEGIN{awk语句};{处理中};END{awk语句}'
'BEGIN{awk语句};{处理中}'
'{处理中};END{awk语句}'引用shell变量需用双引号引起
1.3 工作原理
awk -F: '{print $1,$3}' /etc/passwd-
awk使用一行作为输入,并将这一行赋给内部变量$0,每一行也可称为一个记录,以换行符(RS)结束
-
每行被间隔符
:(默认为空格或制表符)分解成字段(或域),每个字段存储在已编号的变量中,从$1开始问:awk如何知道用空格来分隔字段的呢?
答:因为有一个内部变量
FS来确定字段分隔符。初始时,FS赋为空格制表符(Tab)是一种特殊字符,ASCII 码为 9(十六进制 0x09),通常写作 \t。作用是在在文本中创建水平对齐的列,类似表格的效果。可变宽度(默认 8 个字符位置),自动对齐到下一个制表位(Tab stop) 显示制表符 : cat -T [root@localhost ~]# cat -T sss.txt a^Ib^Ic e^If^Ig -
awk使用print函数打印字段,打印出来的字段会以空格分隔,因为\$1,\$3之间有一个逗号。逗号比较特殊,它映射为另一个内部变量,称为输出字段分隔符OFS,OFS默认为空格
-
awk处理完一行后,将从文件中获取另一行,并将其存储在$0中,覆盖原来的内容,然后将新的字符串分隔成字段并进行处理。该过程将持续到所有行处理完毕
2、awk内置变量
2.1 内部变量
| 变量 | 变量说明 | 备注 |
|---|---|---|
| $0 | 当前处理行的所有记录 | |
| \$1,\$2,\$3…\$n | 文件中每行以间隔符号分割的不同字段 | awk -F: ‘{print \$1,\$3}’ |
| NF | 当前记录的字段数(列数) | awk -F: ‘{print NF}’ |
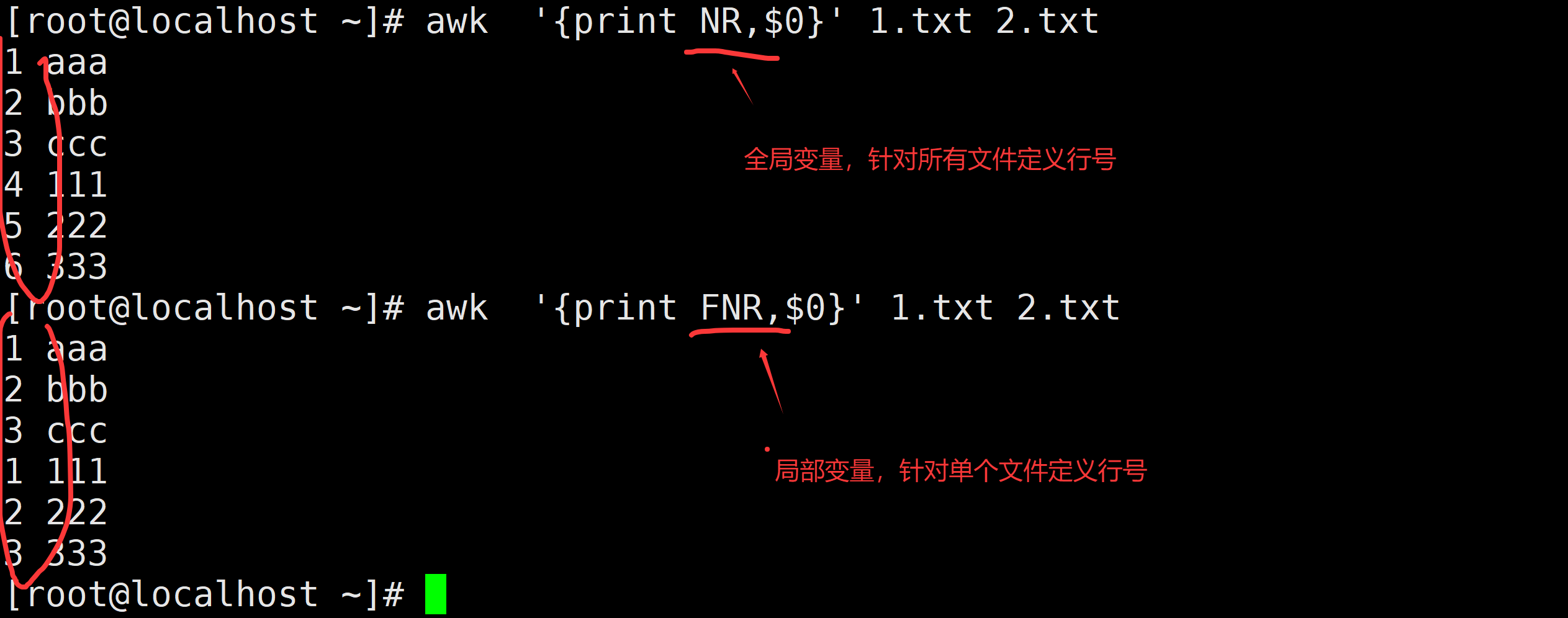
| $NF | 最后一列 | $(NF-1)表示倒数第二列 |
| FNR/NR | 行号 | |
| FS | 定义间隔符 | ‘BEGIN{FS=”:”};{print \$1,$3}’ |
| OFS | 定义输出字段分隔符,默认空格 | ‘BEGIN{OFS=”\t”};print \$1,$3}’ |
| RS | 输入记录分割符,默认换行 | ‘BEGIN{RS=”\t”};{print $0}’ |
| ORS | 输出记录分割符,默认换行 | ‘BEGIN{ORS=”\n\n”};{print \$1,$3}’ |
| FILENAME | 当前输入的文件名 |
格式化输出:
%s 字符类型 strings
%d 数值类型
示例:%-20s-表示左对齐,默认是右对齐
printf默认不会在行尾自动换行,加\n
20表示20个字符
完整示例:
awk -F: ‘{printf “%-20s %-20s %-20s\n”, $1,$2,$3}’ abc.txt
2.2 课堂案例
前提:在家目录中创建文件abc.txt,在文件中添加如下数据:
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm root:/var/adm:/sbin/nologin
root:x:4:7:lp:/var/spool/lpd:/sbin/nologin
woniuxy@com.cn
aa@bb@cc@dd@ee需求1:以冒号进行分割,获取第一列与倒数第二列,最后一列的数据
awk -F: '{print $1,$(NF-1),$NF}' abc.txt需求2:以冒号进行分割,获取第一列与倒数第二列,最后一列的数据,并显示每一行的总列数
awk -F: '{print $1,$(NF-1),$NF,NF}' abc.txt需求3:打印包含root的行数据
awk '/root/{print $0}' abc.txt需求4:打印包含root的行数据,以冒号进行分割,只显示第一列与第二列
awk -F: '/root/{print $1,$2}' abc.txt需求5:显示第一行到第三行的数据
awk 'NR==1,NR==3{print $0}' abc.txt需求6:显示第一行到第三行中以root开头的数据
awk 'NR==1,NR==3{print $0}' abc.txt | awk '/^root/{print $0}'需求7:定义间隔符为@,打印第一列数据以及第二列数据
awk -F@ '{print $1,$2}' abc.txt
awk 'BEGIN{FS="@"};{print $1,$2}' abc.txt需求8:定义间隔符为@,定义输出字段分隔符为制表符\t,打印第一列与最后一列数据
awk 'BEGIN{FS="@";OFS="\t\t"};{print $1,$NF}' abc.txt
OFS="\t\t":指定输出字段分隔符为两个制表符(增强可读性)。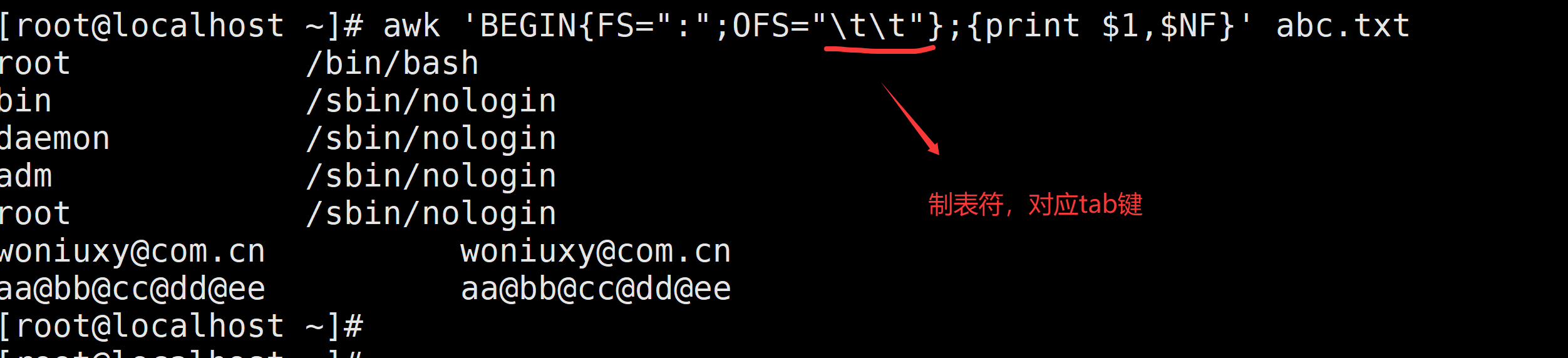
需求9:以冒号进行分割,打印第一列,第二列,第三列数,格式化输出-左对齐,20个字符

awk -F: '{printf "%-20s %-20s %-20s\n", $1,$2,$3}' abc.txt
%s:输出字符串类型字段。
-:左对齐(默认右对齐)。
20:字段宽度为 20 个字符,不足则补空格。
\n:每行末尾添加换行符。在 awk 中,print 和 printf 是两种常用的输出命令,它们的主要区别在于格式化控制和输出行为。以下是详细对比和示例:
| 特性 | print |
printf |
|---|---|---|
| 格式化 | 自动分隔字段,无法自定义格式 | 必须使用格式化字符串,完全自定义 |
| 换行符 | 自动在末尾添加换行符 \n |
不自动添加,需手动指定 \n |
| 参数处理 | 直接打印所有参数 | 需要格式化字符串匹配参数数量 |
3、begin-end语法
3.1 语法
BEGIN{开始处理之前};{处理中};END{处理结束后}
BEGIN:表示在程序开始前执行
END:表示所有文件处理完后执行3.2 课堂案例
需求:以下格式打印abc.txt中第一列与最后一列数据
Login_shell Login_home
************************
/bin/bash /root
/sbin/nologin /bin
/sbin/nologin /sbin
************************************
awk -F: 'BEGIN{print "Login_shell\t\tLogin_home\n***************************************************"};{print $1"\t\t"$NF};END{print "***************************************************"}' abc.txt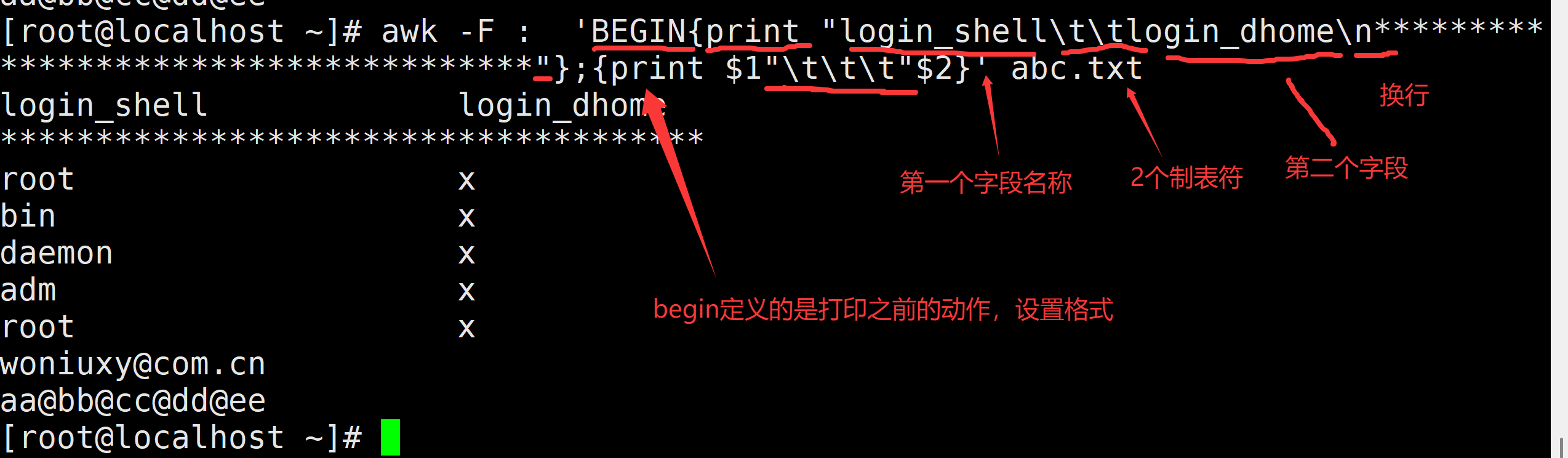
需求2:以下格式打印abc.txt中第一行到第三行中第一列与最后一列数据
awk -F: 'BEGIN{print "Login_shell\t\tLogin_home\n***************************************************"};NR==1,NR==3{print $1"\t\t"$NF};END{print "***************************************************"}' abc.txt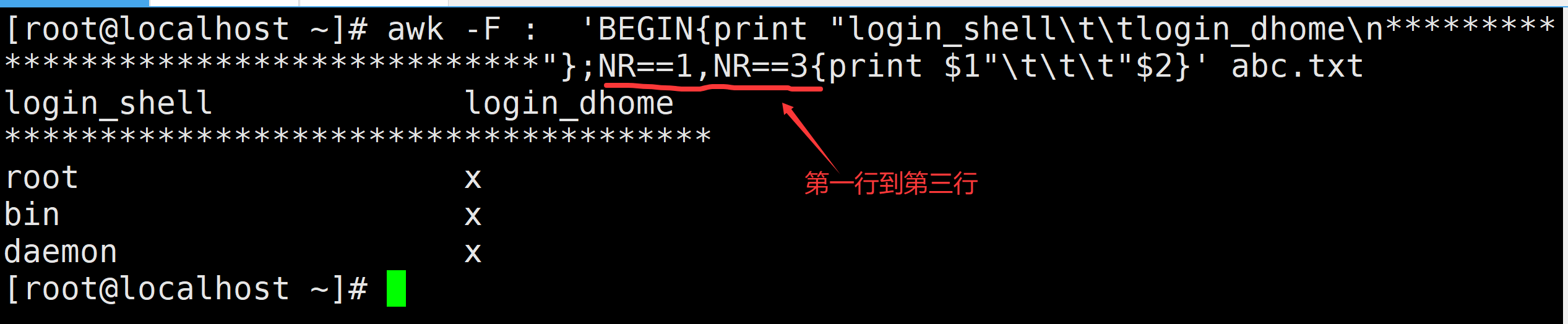
3.3 课堂练习
需求:打印/etc/passwd里的用户名、家目录及登录shell,以下格式打印
u_name h_dir shell
***************************
***************************[root@localhost opt]# awk -F: 'BEGIN{print "u_name\t\th_dir\t\tshell\n************************************************"};{print $1"\t\t"$(NF-1)"\t\t"$NF};END{print "***********************************************************"}' abc.txt 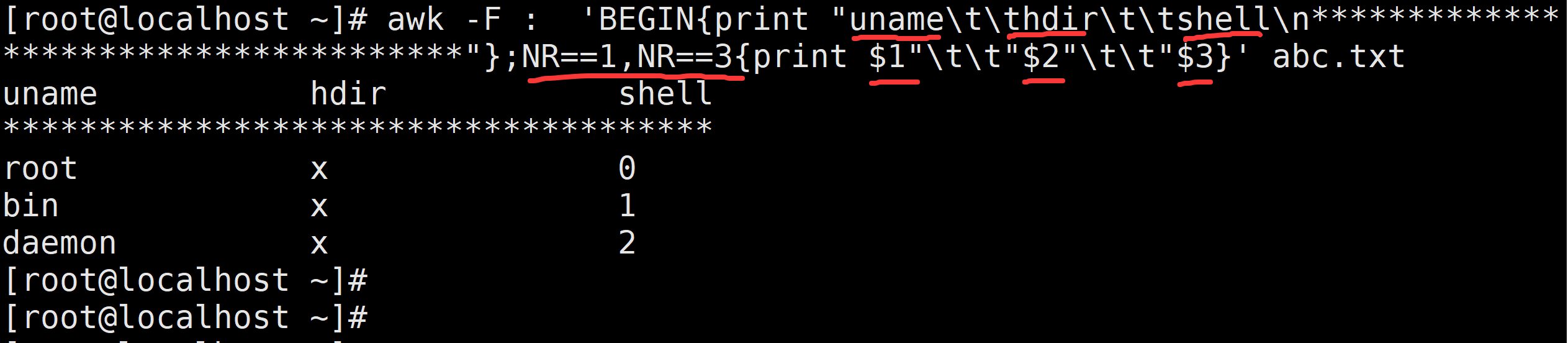
4、awk结合正则
| 运算符 | 说明 |
|---|---|
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| ~ | 匹配 |
| !~ | 不匹配 |
| ! | 逻辑非 |
| && | 逻辑与 |
| || | 逻辑或 |
需求1:从第一行开始匹配到以adm开头行
awk 'NR==1,/^adm/{print $0}' abc.txt
需求2:打印以root开头的行
awk '/^root/{print $0}' abc.txt
需求3:打印以root开头或者以adm开头的行
awk '/^root/ || /^adm/{print $0}' abc.txt
需求4:打印1-3行中以root开头的内容
awk 'NR>=1 && NR<=3 && /^root/{print $0}' abc.txt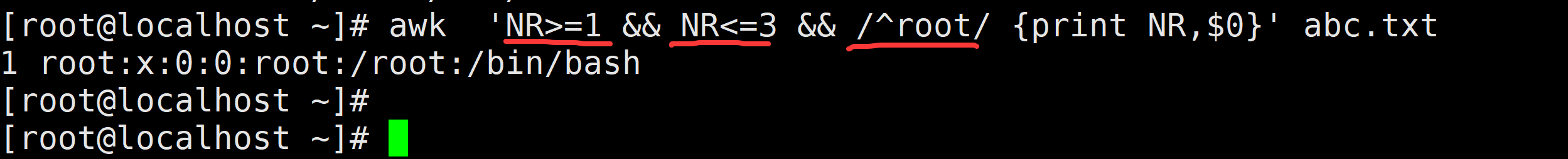
5、流程控制
5.1 流程控制语句
shell中的流程控制语句:
if [ xxx ];then
xxx
fiawk中的流程控制语句:
格式一:
awk 选项 '正则,地址定位{awk语句}' 文件名
{ if(表达式){语句1;语句2;...}}
awk -F : '{ if ($4 > 5) print $1, "系统用户" }' /etc/passwd
格式二:
awk 选项 '正则,地址定位{awk语句}' 文件名
{if(表达式){语句;语句;...}else{语句;语句;...}}
awk -F: '{
if ($4 > 1000) {
print $4,"---普通用户"
} else {
print $4,"---系统用户"
}
fi
}' /etc/passwd
格式三:
awk 选项 '正则,地址定位{awk语句}' 文件名
{ if(表达式1){语句;语句;...}else if(表达式2){语句;语句;...}else if(表达式3){语句;语句;...}else{语句;语句;...}}
awk '{
if ($3 == "ERROR" && $5 > 5) {
print "严重错误: " $0
count++ # 统计错误次数
}
else if ($3 == "WARNING") {
print "警告: " $0
}
}' log.txt
awk -F: '{
if ($4 == 0) {
print $4,"---管理员"
}
else if ($4>=1 && $4<1000){
print $4,"---系统用户"
}
else {
print $4,"---普通用户"
}
fi
}' /etc/passwd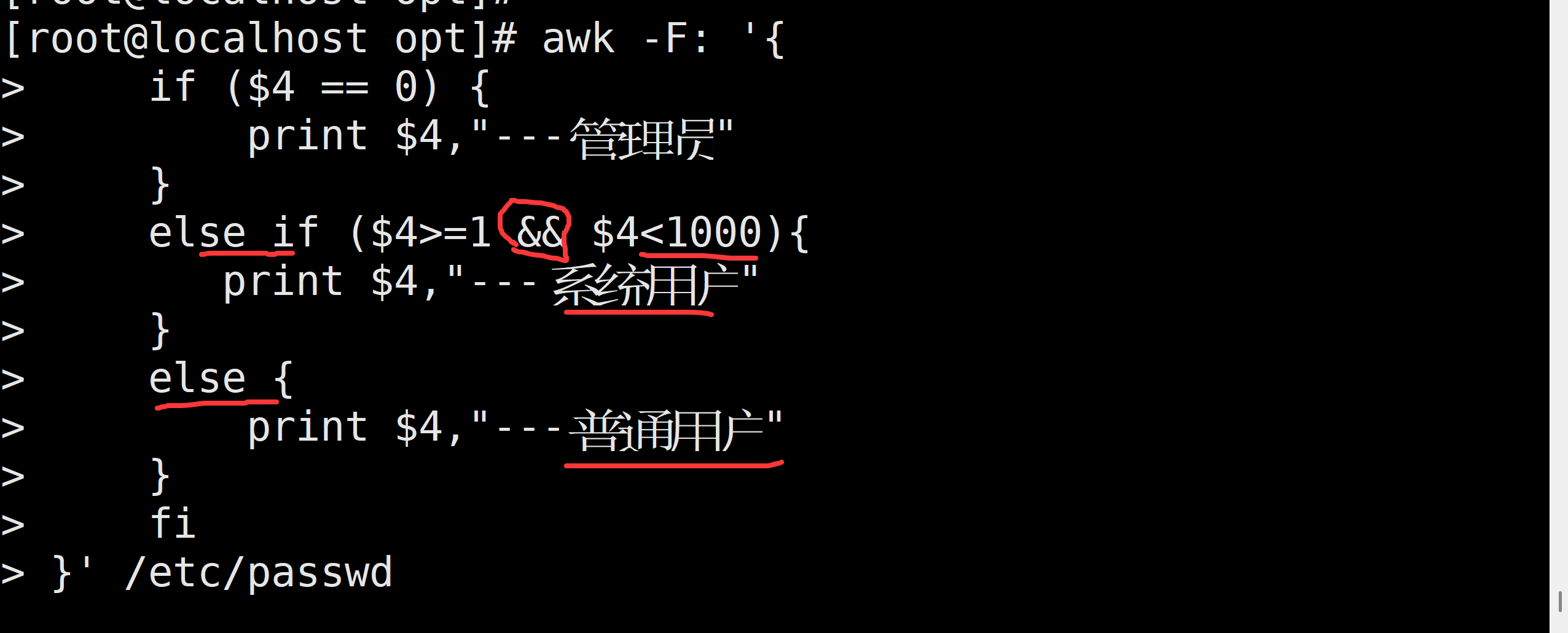
5.2 循环控制语句
while:
# awk 'BEGIN {
i=1;
while(i<=10)
{print i;i++}
}'
由于 BEGIN 块在处理输入前执行,这个命令可以直接运行,无需指定输入文件
for:
# awk 'BEGIN { for(i=1;i<=5;i++) {print i} }'5.3 课堂案例
需求1:统计/etc/passwd 中各种类型shell的数量
#!/bin/bash
# 1. 定义个关联数据,用存储shell的类型及其数量
declare -A shells
# 2. 切割获取最后一行的数据,临时存在到一个文件中tmp.txt
awk -F : '{print $NF}' /etc/passwd > tmp.txt
# 3. 循环读取tmp.txt文件
while read s
do
# 每读取一行,就是一个shell类型,这个shell类型有可能在数组中,也有可能不存在
# 如果不存在,在加入到关联数组中,并且出现的次数1
# 如果存在,则在原来的值的基础上在加1
let shells[$s]++
done < tmp.txt
# 4. 遍历数组,将关联数组中的数据读取出来
for s in "${!shells[@]}"
do
echo "$s出现的次数为:${shells[$s]}"
doneawk -F: '{ shells[$NF]++ };END{for (i in shells) {print i,shells[i]} }' /etc/passwd
shells[$NF]++:以 shell 名称为索引,对关联数组 shells 进行计数累加。
awk 的数组可以使用字符串作为索引(如 shells["/bin/bash"]),无需预定义。
若数组元素不存在,首次引用时会自动初始化为 0(如 shells["/bin/bash"]++)。
for (i in shells):遍历数组的所有索引(即不同的 shell 名称)
print i, shells[i]:输出 shell 名称及其对应的用户数量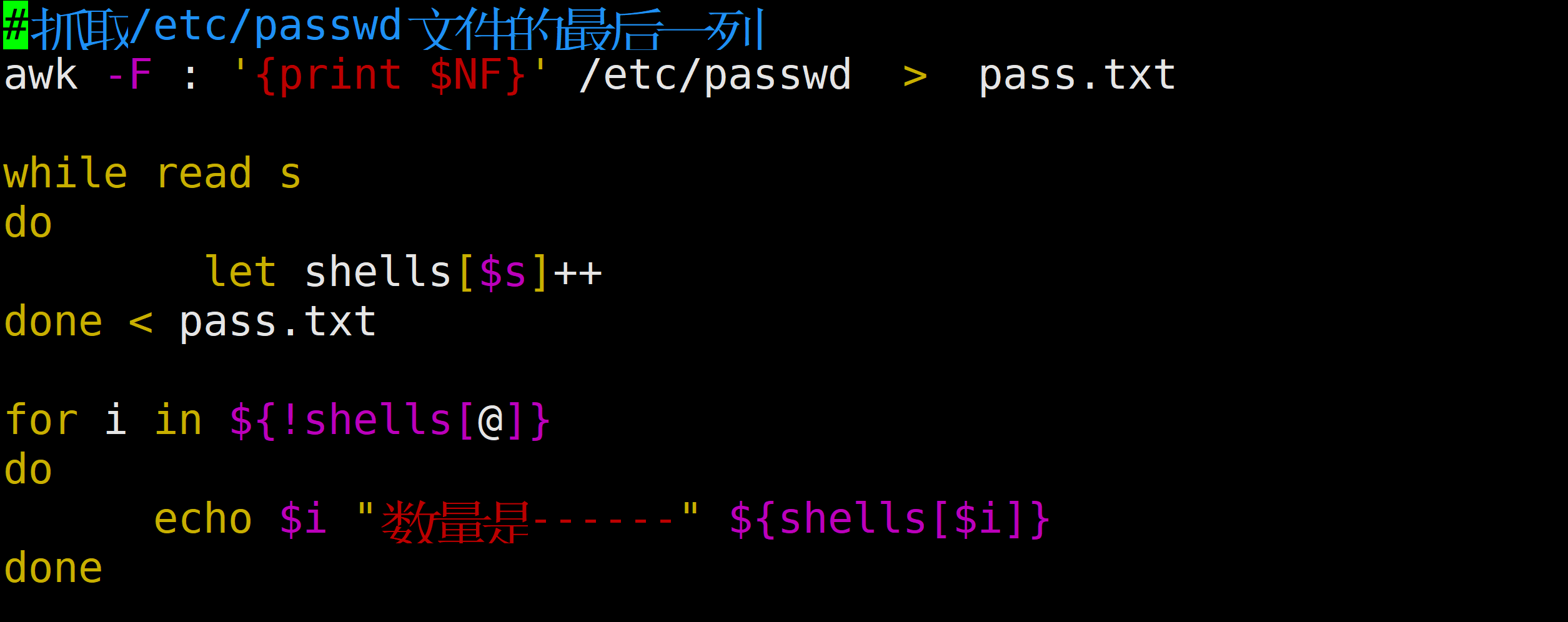
20.shell综合
20.1 防火墙
#!/bin/bash
# 防火墙相关设置
systemctl stop firewalld &>/dev/null
systemctl disable firewalld &>/dev/null
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
echo "关闭防火墙成功"20.2 主机名
# 设置主机名
if [ $# -eq 0 ];then
hostnamectl set-hostname server.com &>/dev/null
else
hostnamectl set-hostname $1 &>/dev/null
fi
echo "设置主机名成功"20.3 yum源
# 配置yum源
# 看网络是否可以ping通
ping -c1 www.baidu.com &>/dev/null
if [ ! $? -eq 0 ];then
echo "网络不通,请先确认网路是否通畅,退出脚本"
exit
fi
# 先通过yum安装wget
yum install wget -y &>/dev/null
# 备份之前的镜像源
cd /etc/yum.repos.d/
tar -zcvf repo.tar.gz *.repo
rm -rf *.repo
# 配置阿里镜像源
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.rep
yum clean all
yum makecache
# 安装扩展镜像源
yum install epel-release -y#!/bin/bash
# 防火墙相关设置
systemctl stop firewalld &>/dev/null
systemctl disable firewalld &>/dev/null
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
echo "关闭防火墙成功"
# 设置主机名
if [ $# -eq 0 ];then
hostnamectl set-hostname server.com &>/dev/null
else
hostnamectl set-hostname $1 &>/dev/null
fi
echo "设置主机名成功"
# 配置yum源
# 看网络是否可以ping通
ping -c1 www.baidu.com &>/dev/null
if [ ! $? -eq 0 ];then
echo "网络不通,请先确认网路是否通畅,退出脚本"
exit
fi
# 先通过yum安装wget
yum install wget -y &>/dev/null
# 备份之前的镜像源
cd /etc/yum.repos.d/
tar -zcvf repo.tar.gz *.repo &>/dev/null
rm -rf *.repo
# 配置阿里镜像源
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo &>/dev/null
yum clean all &>/dev/null
yum makecache &>/dev/null
# 安装扩展镜像源
yum install epel-release -y &>/dev/null
echo "yum源配置成功"20.4 安装MySQL
# 安装MySQL
# 1. 检查MySQL源码包是否已经上传
# 2. 检查并创建用户
# 3. 解压缩软件并进入MySQL目录
# 4. 源码配置,安装必要的依赖
# 5. 执行配置选项
# 6. 编译并安装
# 7. 更改数据目录权限
# 8. 初始化数据库
# 9. 拷贝启动脚本
# 10. 启动数据库
# 11. 设置密码# 下载MySQL
wget http://dev.mysql.com/get/Downloads/MYSQL-5.6/mysql-5.6.31.tar.gz
# 安装MySQL
# 1. 检查MySQL源码包是否已经上传
if [ ! -e /root/mysql-5.6.31.tar.gz ];then
echo "MySQL安装包不存在,请检查是否上传MySQL安装包"
exit
fi
# 2. 检查并创建用户
echo "创建mysql用户"
cut -d: -f1 /etc/passwd | grep -w mysql
if [ $? -eq 0 ];then
echo "mysql用户已存在!"
else
useradd -r -s /sbin/nologin mysql
echo "mysql用户创建成功!"
fi
# 3. 解压缩软件并进入MySQL目录
echo "解压mysql源码文件"
# 解压缩mysql
tar zxvf ~/mysql-5.6.31.tar.gz
cd ~/mysql-5.6.31
# 4. 源码配置,安装必要的依赖
echo "正在安装必要的一些依赖....."
# 提供 C++ 编译环境,MySQL 源码编译需要 C++ 编译器支持
yum install gcc-c++ -y
# 生成 Makefile 文件,控制编译过程
yum install cmake -y
# cmake 是一个跨平台的构建工具,用于生成编译所需的 Makefile 或项目文件。在编译 MySQL 时,CMake 用于配置编译选项、检查依赖和生成构建系统。
# 提供终端界面开发库,用于 MySQL 命令行工具(如 mysql、mysqladmin)
yum -y install ncurses-devel
# 自动配置软件源代码,生成 configure 脚本
yum -y install autoconf
# 5. 执行配置选项
echo "正在配置MySQL....."
if [ -e ~/mysql-5.6.31/CMakeCache.txt ];then
rm -rf ~/mysql-5.6.31/CMakeCache.txt
fi
cmake . \
# 指定 MySQL 的安装根目录,所有二进制文件、配置文件都将安装在此目录下
-DCMAKE_INSTALL_PREFIX=/usr/local/mysql/ \
# 指定 MySQL 数据库文件(如数据表、索引)的存储目录
-DMYSQL_DATADIR=/usr/local/mysql/data \
# 启用 LOAD DATA LOCAL INFILE 功能,允许从客户端本地导入数据
-DENABLED_LOCAL_INFILE=1 \
# 启用 InnoDB 存储引擎(MySQL 5.5+ 默认引擎,支持事务、外键)
-DWITH_INNOBASE_STORAGE_ENGINE=1 \
# 设置 MySQL 服务监听的 TCP 端口号(默认 3306)
-DMYSQL_TCP_PORT=3306 \
# 设置默认字符集为 utf8mb4(支持完整 Unicode,包括 emoji 表情)
-DDEFAULT_CHARSET=utf8mb4 \
# 设置默认排序规则为 utf8mb4_general_ci(不区分大小写)
-DDEFAULT_COLLATION=utf8mb4_general_ci \
# 安装所有额外字符集支持
-DWITH_EXTRA_CHARSETS=all \
# 指定运行 MySQL 服务的系统用户(通常为 mysql)
-DMYSQL_USER=mysql
cmake . \
-DCMAKE_INSTALL_PREFIX=/usr/local/mysql/ \
-DMYSQL_DATADIR=/usr/local/mysql/data \
-DENABLED_LOCAL_INFILE=1 \
-DWITH_INNOBASE_STORAGE_ENGINE=1 \
-DMYSQL_TCP_PORT=3306 \
-DDEFAULT_CHARSET=utf8mb4 \
-DDEFAULT_COLLATION=utf8mb4_general_ci \
-DWITH_EXTRA_CHARSETS=all \
-DMYSQL_USER=mysql
# 6. 编译并安装
echo "正在编译安装MySQL....."
make && make install
# 7. 更改数据目录权限
chown -R mysql.mysql /usr/local/mysql/
# 8. 初始化数据库
echo "初始化数据库文件"
rm -f /etc/my.cnf
pkill -9 mysqld
cd /usr/local/mysql/
./scripts/mysql_install_db --user=mysql
# 9. 拷贝启动脚本
echo "拷贝启动脚本"
if [ ! -e /etc/init.d/mysql ];then
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
fi
# 10. 启动数据库
echo "启动数据库"
service mysql start
# 11. 设置密码
echo "设置密码"
/usr/local/mysql/bin/mysqladmin -u root password '123456'
# 12. 配置环境变量
echo "设置环境变量"
grep "/usr/local/mysql/bin/" /etc/profile
if [ ! $? -eq 0 ];then
echo 'export PATH=/usr/local/mysql/bin/:$PATH' >> /etc/profile
source /etc/profile
fi21.until循环
1 语法结构
特点:条件为假就进入循环;条件为真就退出循环
until 条件表达式
do
command
command
...
done示例
i=1
until [ $i -gt 5 ]
do
echo $i
let i++
done

2 课堂案例
需求:使用until循环打印1-10之间的数字
#!/bin/bash
i=1
until [ $i -gt 10 ]
do
echo $i
let i++
done